
How Mid-Market Revenue Teams Should Structure Their First Agentic GTM Experiment
Nearly 90% of mid-market companies plan to implement AI in 2026, according to CBS News. Yet most teams treat their first agentic GTM experiment like a hackathon and end up with a proof-of-concept that never ships. The teams that succeed treat it differently: as a structured pilot-to-production program with clear governance, measurable KPIs, and human oversight baked in from day one. This playbook shows exactly how to do that — covering use-case selection, 30-60-90 day milestones, RACI design, and the KPIs that actually matter for revenue operations teams.
Build Pipeline Faster With Apollo
Tired of burning hours on manual lead research while your pipeline stalls? Apollo delivers verified contacts and scalable playbooks so your team spends less time digging and more time closing. Join 600K+ companies building predictable pipeline.
Start Free with Apollo →Key Takeaways
- Start with a "time-recovered" wedge use case — pick one workflow where an agent handles admin or research so reps spend more time selling.
- Structure the experiment in three gated phases (30/60/90 days) with explicit pass/fail criteria before expanding agent autonomy.
- Build human-in-the-loop controls first. Earn autonomy through metrics — don't grant it on day one.
- Adoption readiness and data quality are bigger failure risks than model choice or tooling.
- RevOps leaders who consolidate their GTM tech stack before launching an agentic experiment remove the biggest integration bottlenecks.
Why Do Mid-Market Revenue Teams Need a Structured Agentic GTM Experiment?
Mid-market revenue teams need a structured experiment because their constraints are fundamentally different from enterprise: smaller RevOps headcount, tighter budgets, and no dedicated AI engineering team to clean up failed pilots. A structured approach converts a risky one-off test into a repeatable program that CFOs and CROs can fund confidently.
The urgency is real. Research from Landbase shows that 79% of organizations reported some level of AI agent adoption as of 2025, with 96% planning to expand usage. Mid-market teams that delay risk handing pipeline coverage advantages to competitors who move first. The goal isn't AI for its own sake — it's recovering selling time and routing better leads.
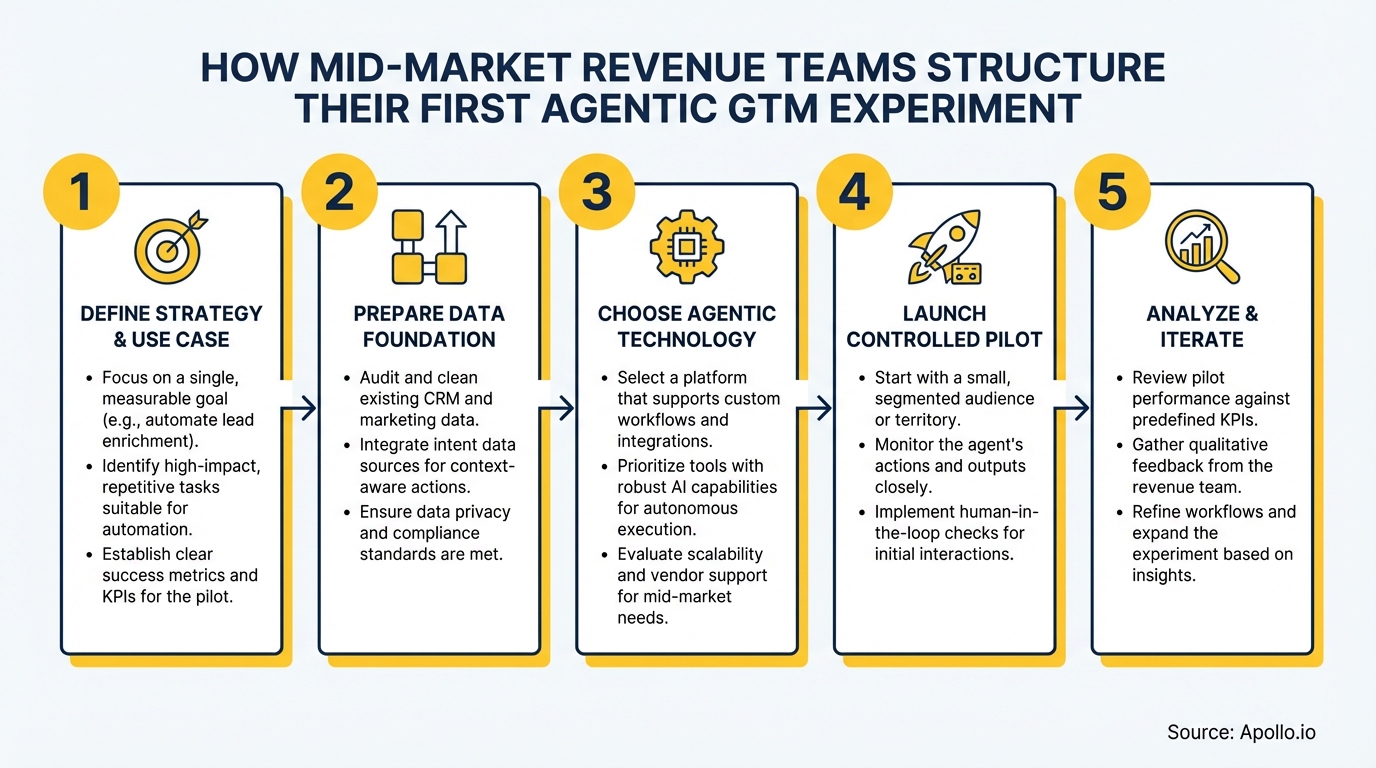
How Do RevOps Leaders Choose the Right First Use Case?
RevOps leaders should choose a "time-recovered" wedge use case: a workflow where the agent handles repetitive admin or research tasks, freeing reps to focus on revenue-generating conversations. This is the highest-signal starting point because it produces measurable ROI without requiring the agent to communicate directly with buyers.
What Are the Best First Use Cases by Role?
| Role | Recommended First Use Case | Primary KPI |
|---|---|---|
| SDR / BDR | Agent-researched prospect briefs before outreach | Research time recovered per rep per week |
| Account Executive | Pre-meeting account summaries pulled from CRM + intent signals | Meeting prep time recovered; win rate on prepped vs. unprepped calls |
| RevOps | Automated CRM data enrichment and contact routing | Data accuracy rate; lead routing SLA |
| Marketing Ops | Agent-drafted first-touch email personalization (approve-to-send) | Reply rate; brand error rate per 100 sends |
Prioritize use cases where the agent output is reviewed by a human before it reaches a buyer. This "approve-to-send" gate protects brand risk while you gather the accuracy data needed to earn greater autonomy later. For SDRs and BDRs, pairing agent-generated research with intent data signals dramatically improves the quality of that research output.
Spending hours manually researching prospects before every outreach sequence? Let Apollo's AI sales automation handle account research so your reps can focus on conversations that close.
What Does a 30-60-90 Day Pilot-to-Production Plan Look Like?
A 30-60-90 day structure gives mid-market teams three gated phases: build and baseline, measure and refine, then scale or kill. Each phase has explicit pass/fail criteria so the experiment advances on evidence, not enthusiasm.
| Phase | Focus | Gate Criteria to Advance |
|---|---|---|
| Days 1–30 | Define use case, configure agent, establish baselines (current time-on-task, data quality score, error rate) | Agent output reviewed and rated by reps; baseline metrics captured |
| Days 31–60 | Run approve-to-send workflow with pilot cohort (5–10 reps); log errors, brand risks, escalations | Error rate below agreed threshold; rep satisfaction score above 3.5/5 |
| Days 61–90 | Expand cohort or reduce human review gate; calculate time recovered and pipeline contribution | Positive time-recovery ROI; no unresolved compliance or data-privacy flags |
According to KeyBank's mid-market research, many mid-market leaders take a phased approach — starting with smaller technology investments to validate impact and then reinvesting based on proven returns. The 30-60-90 structure operationalizes exactly that philosophy. For broader context on building a scalable GTM strategy, the phased pilot model maps directly to how high-growth teams sequence their go-to-market investments.
Turn Funnel Gaps Into Pipeline With Apollo
Pipeline forecasting a guessing game? Apollo surfaces quality leads and tracks deal momentum in real time. Nearly 100K paying customers stopped guessing and started closing.
Start Free with Apollo →How Do Mid-Market Teams Build Governance and Human-in-the-Loop Controls?
Governance for an agentic GTM experiment means defining who owns the agent, who reviews its outputs, when it must escalate to a human, and what data it can access. These rules must be documented before the pilot starts — not retrofitted after something goes wrong.
A significant 92% of companies using generative AI encountered challenges during rollout, with data quality (41%), data privacy and security (39%), and insufficient internal skills (35%) as the most common issues, per RSM's middle-market AI research. Governance design directly addresses all three.
What Should a RACI Model Look Like for an Agentic GTM Pilot?
- Responsible: RevOps manager (agent configuration, data permissions, error logging)
- Accountable: VP of Sales or CRO (pilot go/no-go decisions, budget approval)
- Consulted: SDR team lead (use-case feedback, rep adoption blockers), Legal/Security (data access scope)
- Informed: Marketing Ops, Sales Enablement (downstream workflow changes)
Escalation rules should be explicit: if the agent produces output flagged as off-brand, factually uncertain, or touching a prospect already in active deal stages, it routes to human review automatically. This mirrors the supervised autonomy model that platforms like Salesforce's Agentforce Contact Center validated in early 2026 — live transcript visibility combined with defined escalation triggers.

How Do SDRs and AEs Measure Time-Recovery ROI from Agentic Workflows?
SDRs and AEs measure time-recovery ROI by comparing time spent on a task before and after the agent handles it, then multiplying recovered hours by the average revenue value of a rep's selling hour. This makes the business case concrete for CROs and CFOs without requiring complex attribution models.
Key metrics to track from day one:
- Time recovered per rep per week (research, CRM updates, email drafting)
- Agent error rate (factual mistakes, brand violations, wrong contact targeted) per 100 outputs
- Rep adoption rate (% of pilot cohort actively using agent outputs vs. ignoring them)
- Pipeline contribution (meetings booked or opportunities progressed from agent-assisted outreach)
- Cost per agent-assisted action (especially relevant as pricing shifts from per-seat to usage-based models)
For AEs, the clearest early signal is win rate on calls where agent-generated pre-meeting briefs were used versus calls without them. This isolates the agent's contribution without needing to overhaul attribution across the full funnel. Pairing this with sales analytics gives RevOps a complete picture of where agents are moving the needle.
Struggling to build a clean pipeline that agents can actually work with? Apollo's pipeline tools give RevOps teams verified, enriched contacts that feed agentic workflows with accurate data from day one.
What Tech Stack and Data Readiness Do You Need Before Launching?
Before launching an agentic GTM experiment, your CRM data must be clean enough for an agent to act on it reliably. Agents amplify data quality problems — a bad contact record doesn't just waste a rep's time, it sends a personalized sequence to the wrong person at scale.
A recommended pre-launch checklist from Forbes Technology Council includes: identifying strong and accessible data, structuring unorganized data, capturing expert knowledge, and deploying agents that integrate with existing workflows before iterating based on feedback. Mid-market teams that consolidate their sales tech stack before the pilot remove the biggest integration bottleneck. As Predictable Revenue put it: "We reduced the complexity of three tools into one" — a unified platform means agents have one clean data source to read from and write to, not five. See how that consolidation works in the Predictable Revenue customer story.
For teams building their sales tech stack ahead of an agentic pilot, prioritize platforms with native enrichment, engagement, and CRM sync — so agents operate from a single source of truth rather than stitching together data across disconnected tools.

How Do Mid-Market Revenue Teams Turn Their First Agentic GTM Experiment into a Scalable Program?
Turning a pilot into a scalable program requires two things: documented evidence that the pilot met its gate criteria, and a repeatable operating model that the next cohort of reps can adopt without starting from scratch.
After Day 90, high-performing teams produce a one-page pilot readout covering: time recovered, error rate trend, pipeline contribution, rep adoption rate, and open compliance flags. This readout becomes the funding request for Phase 2.
Teams that skip this step often see pilots quietly abandoned when the champion moves on or budget cycles reset.
The broader market is moving fast. As generative AI adoption among middle-market companies reached 91% in 2025 — up from 77% the prior year, per RSM's 2025 AI Survey — the question is no longer whether to run an agentic experiment, but whether yours produces results fast enough to matter. The teams winning in 2026 start narrow, govern tightly, measure rigorously, and scale what works. For a deeper look at building the revenue operations foundation that makes all of this possible, start with Apollo's revenue operations framework.
Apollo brings prospecting, enrichment, multi-channel engagement, and AI automation into one platform — so your agentic GTM experiment runs on clean data and a unified workflow from the start. Start Your Free Trial and give your first agentic pilot the data foundation it needs to ship.
Prove Pipeline ROI With Apollo
ROI pressure killing your budget approvals? Apollo delivers measurable pipeline impact — fast. Leadium 3x'd their annual revenue using Apollo's automation. Start your free trial and show results before your next review.
Start Free with Apollo →Don't miss these
Sales
Inbound vs Outbound Marketing: Which Strategy Wins?
Sales
What Is a Sales Funnel? The Non-Linear Revenue Framework for 2026
Sales
What Is a Go-to-Market Strategy? The 2026 GTM Playbook
See Apollo in action
We'd love to show how Apollo can help you sell better.
By submitting this form, you will receive information, tips, and promotions from Apollo. To learn more, see our Privacy Statement.
4.7/5 based on 9,015 reviews
