
How to Schedule Regular Data Syncs Between Different Systems in 2026
Disconnected systems quietly drain revenue. According to Kellton, data silos cost businesses an average of $3.1 trillion annually in lost revenue. For RevOps leaders and GTM teams, that cost shows up as stale CRM records, misrouted leads, and pipeline visibility gaps. Scheduling regular data syncs between your systems is the operational fix — but only if you build it right. This guide covers the patterns, governance, and reliability practices that separate fire drills from stable pipelines. For a broader look at sync challenges, see Solving Data Synchronization Headaches Across Multiple Business Systems.
Research Less, Pipeline More With Apollo
Tired of your reps burning hours verifying contact info instead of closing deals? Apollo surfaces accurate, ready-to-reach prospects instantly. Join 600K+ companies turning research time into revenue.
Start Free with Apollo →Key Takeaways
- Choose your sync pattern (CDC, incremental, or snapshot) based on data freshness requirements and failure tolerance — not just convenience.
- Data quality is the top blocker for reliable syncs; governance gates and schema drift monitoring must be built into the schedule, not bolted on later.
- Treat one system as the authoritative source of record to avoid dual-write failures and ghost records.
- RevOps and data teams should design sync SLAs around business impact — lead routing delays, scoring lag, and campaign enrollment windows all have measurable costs.
- AI-readiness is now a first-class sync requirement: freshness SLAs, lineage tracking, and validation gates determine whether your models get clean inputs.
Why Does Scheduling Data Syncs Between Systems Matter in 2026?
Regular data syncs keep every system in your stack operating from the same ground truth. Research from RudderStack shows 82% of enterprises report that data silos plague critical workflows — meaning the majority of GTM teams are making decisions on incomplete or outdated records. The global data integration market is projected to grow from USD 17.58 billion in 2025 to USD 33.24 billion by 2030, according to MarketsandMarkets — a signal that demand for reliable cross-system sync is accelerating, not plateauing.
For B2B GTM teams specifically, sync failures mean leads routed to the wrong rep, scoring models fed stale firmographics, and campaign enrollment that fires days late. Those aren't data problems — they're revenue problems. A solid data enrichment strategy depends on fresh, synchronized data across every touchpoint.
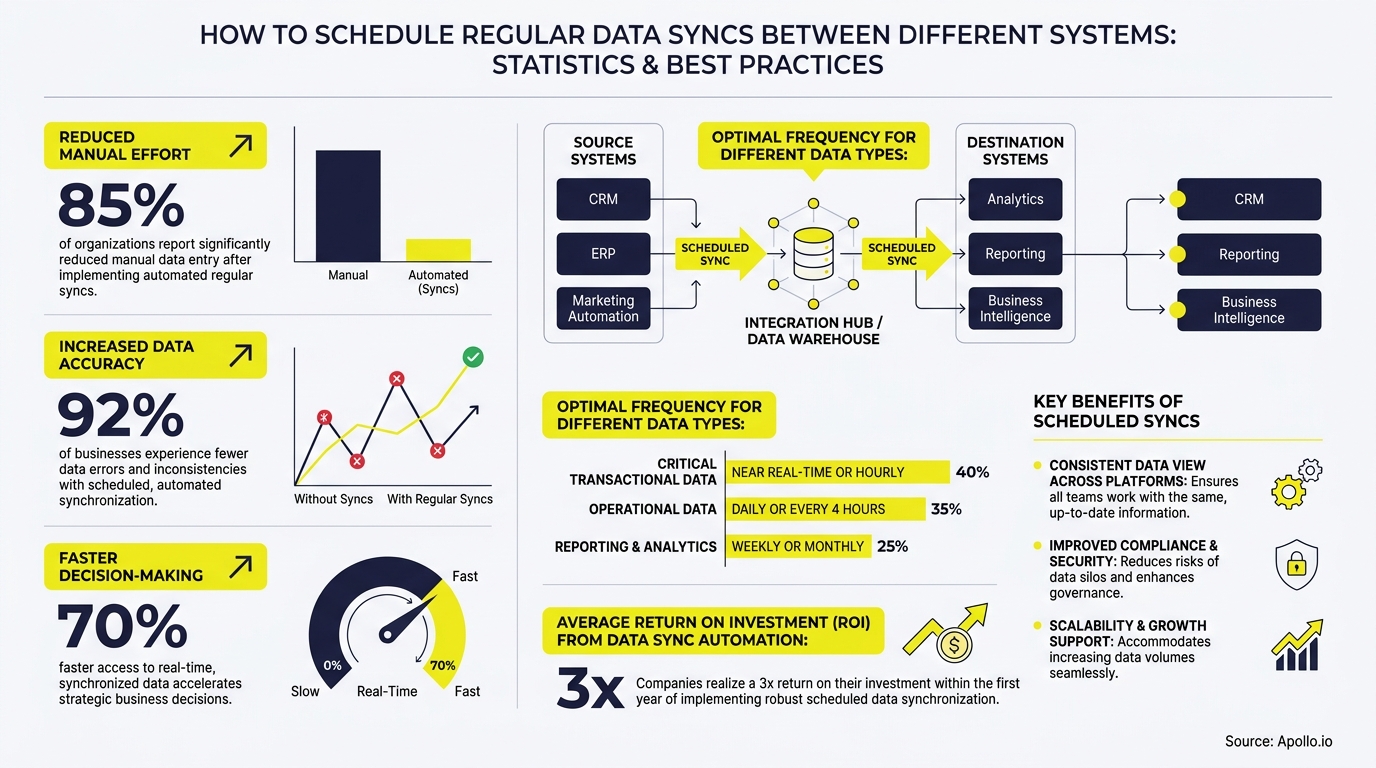
What Are the Main Sync Patterns — CDC, Incremental, and Snapshot?
The three primary patterns for scheduling data syncs are Change Data Capture (CDC), incremental sync, and full snapshot — each with distinct tradeoffs in freshness, resource cost, and failure recovery.
| Pattern | How It Works | Best For | Key Risk |
|---|---|---|---|
| CDC | Captures row-level changes from the source DB log in near-real-time | High-frequency updates, lead routing, scoring | Log retention limits; complex idempotency handling |
| Incremental | Pulls only records modified since the last sync using a timestamp or cursor | CRM-to-warehouse syncs, daily enrichment jobs | Missed deletes; cursor drift after failures |
| Full Snapshot | Copies the entire dataset on each run | Small reference tables, schema resets, backfills | High resource cost; risky at scale |
A growing best practice in 2026 is the hybrid model: incremental updates run frequently (every 5–15 minutes) while a full refresh fires on a weekly schedule or after schema changes. This controls drift without the cost of constant full copies. A Reddit user shared a firsthand perspectivethat dual-writes are a common trap: the recommended fix is treating one database as the system of record and using an outbox pattern — the app writes once to the source, appends a deterministic event ID to an outbox table, and a worker publishes to a queue that consumers upsert idempotently into the target system.
How Do You Build Reliable, Production-Grade Sync Schedules?
Reliable sync scheduling requires four operational controls: a defined system of record, idempotent consumers, schema drift detection, and a backfill runbook.
- System of record: Designate one authoritative source per data domain (e.g., CRM owns contact stage; warehouse owns firmographic enrichment). All other systems are projections.
- Idempotency: Every consumer must handle duplicate events without corrupting data. Use event ID deduplication tables and version columns.
- Schema drift detection: Add validation gates that compare source and target schemas before each run. Fail fast on unexpected column additions or type changes rather than silently corrupting downstream tables.
- Backfill runbook: Document the exact steps to replay missed events or repair a partial sync. Test it quarterly — not only after an incident.
- API quota awareness: Scheduling decisions must account for vendor API rate limits and retry/backoff behavior, especially as more systems connect to the same CRM.
A second Reddit user added in a Reddit discussiona practical ID-mapping approach for heterogeneous databases: store the source system's primary key as a foreign property on each target document (e.g., a pgId field in MongoDB), so cross-system queries use consistent identifiers regardless of native ID formats.
Tired of stale contact data breaking your outreach? Keep your CRM current with Apollo's verified B2B data enrichment.

How Do RevOps Leaders Define SLAs for Data Sync Pipelines?
RevOps leaders should define sync SLAs around business-impact thresholds, not just technical uptime. The question is: how stale can this data be before it breaks a downstream process?
- Lead routing: Sync lag over 10 minutes can violate speed-to-lead SLAs and reduce connect rates.
- Scoring models: Firmographic enrichment syncing daily is acceptable; behavioral signals feeding a scoring model may need sub-hour freshness.
- Campaign enrollment: Many native integrations poll every 5–10 minutes. Design enrollment timing and alerting around that window rather than assuming instant propagation.
- Reporting dashboards: Revenue leaders typically accept T+1 latency for pipeline reports but need same-day accuracy for forecasting calls.
Pair each SLA with an alert threshold that fires before the SLA is breached, not after. For more on structuring your data layer for GTM outcomes, see how contact data enrichment drives ROI.
Turn Funnel Guesswork Into Closed Deals
Pipeline forecasting a guessing game because quality leads never materialize into opportunities? Apollo surfaces in-market buyers the moment they're ready to act. Join 600K+ companies building pipeline they can actually forecast.
Start Free with Apollo →How Do You Make Scheduled Syncs AI-Ready?
AI-ready sync design means your pipelines deliver data that models can trust: fresh, validated, and traceable. This is no longer optional.
A 2024 survey by Nexla and Ascend2 found 59% of data integration professionals say GenAI and ML-driven integration is a key area requiring investment — and about two-thirds say data quality management will require the most attention going forward.
- Freshness SLAs per model: Define the maximum acceptable data age for each AI feature consuming synced data. Scoring models, routing logic, and personalization engines have different tolerances.
- Lineage tagging: Tag each synced record with its source system, sync job ID, and timestamp so downstream models can trace predictions back to inputs.
- Validation gates: Run automated row-count checks, null-rate assertions, and referential integrity tests before data is promoted to model-ready status.
- Human-in-the-loop exceptions: Route records that fail validation to a review queue rather than dropping or silently passing them. This prevents model drift caused by corrupt inputs.
The shift toward reverse ETL — pushing modeled warehouse outputs back into CRMs and marketing tools on a schedule — adds another layer. Enriched scores and segments flowing back into Salesforce or HubSpot require the same idempotency and drift controls as forward syncs. Review which data enrichment tools drive revenue in 2026 to evaluate where enrichment fits in your sync architecture.
What Observability Practices Keep Sync Schedules Healthy?
Observability for scheduled syncs means monitoring sync lag, failure rates, and data quality metrics continuously — not just checking whether a job completed.
- Lag dashboards: Track time-since-last-successful-sync per pipeline. Alert when lag exceeds the defined SLA threshold.
- Row-count reconciliation: Compare source and target record counts after each run. Unexplained deltas indicate missed deletes, partial failures, or filter drift.
- Error categorization: Separate transient failures (network timeouts, rate limits) from structural failures (schema changes, auth expiry). Each category requires a different response playbook.
- Dead-letter queues: Route failed events to a quarantine queue for inspection and replay rather than discarding them silently.
Tool consolidation is an emerging priority here: having a single orchestration layer that handles scheduling, monitoring, and alerting reduces the cognitive load on data and RevOps teams. For teams managing enrichment pipelines alongside sync jobs, Apollo's CRM enrichment tool keeps contact and account data accurate without requiring a separate maintenance workflow.

Conclusion: Build Sync Schedules That Support Revenue, Not Just Infrastructure
Scheduling regular data syncs between systems is fundamentally a revenue operations discipline, not just an engineering task. The patterns are well-established — choose the right sync model, designate a system of record, build idempotent consumers, and instrument everything.
The gap most teams face is governance: schema drift, SLA definitions, and AI-readiness requirements that get added after the fact instead of designed in from the start.
For B2B GTM teams, clean and synchronized data directly determines lead routing accuracy, scoring model performance, and campaign timing. Pairing data enrichment with regular sync schedules ensures that every system in your stack operates from verified, up-to-date records — not stale snapshots.
Ready to keep your GTM data synchronized and accurate? Start Prospecting with Apollo and consolidate your data enrichment, contact verification, and outreach into one unified platform.
Prove Pipeline ROI Before Next QBR
ROI pressure killing your tool approval? Apollo delivers measurable pipeline impact from day one — no lengthy pilots, no guesswork. Teams like Leadium 3x'd annual revenue. Start free today.
Start Free with Apollo →Don't miss these
Sales
Inbound vs Outbound Marketing: Which Strategy Wins?
Sales
What Is a Sales Funnel? The Non-Linear Revenue Framework for 2026
Sales
What Is a Go-to-Market Strategy? The 2026 GTM Playbook
See Apollo in action
We'd love to show how Apollo can help you sell better.
By submitting this form, you will receive information, tips, and promotions from Apollo. To learn more, see our Privacy Statement.
4.7/5 based on 9,015 reviews
