At Apollo, we use MongoDB as our transactional database, where we store a LOT of data. We have 6 clusters, 120 shards, and 270TB of disks in total. Most of that data could be useful downstream for BI, ML/AI, Security, and more, if we were able to run massive queries on it. So the Data Platform team set out to make this the reality, by moving the MongoDB data into our data lake.
The Challenge
Data Platform’s first customer was Apollo’s BI team. We wanted BI weekly reports to be available by the start of Monday; that gives us a window of ~32 hours (from midnight Sunday, data cutoff, to 8AM Monday) for the whole pipeline - to ingest raw data, run ETL, and build the reports/dashboards. The complexity of ETLs and building reports means we only have ~6 hours to ingest raw Mongo data in order to finish the entire pipeline in 32 hours.
We have 6 hours to move data from 6 Mongo clusters that have 120 shards and 270TB of disks. And we are not allowed to impact production while doing so.
The Journey
Setting the target
We knew we couldn’t simply test on our local machines and assume the results would apply to the production clusters. We needed something that resembled a fraction of production’s scale. Fortunately, the Devops team had set up replication from disk snapshots for one of the clusters for dev work. It’s almost perfect: there is little traffic there, so we could easily spot changes in resource utilization; it’s a replica, so we don’t have to worry about bricking it. The only thing was that it’s our 2nd smallest cluster, we would have to reverify our approach on the larger ones.
So we had our target: ingest data from this staging cluster quickly and efficiently, and replicate that process to the rest.
Testing available tools
We started out by exploring Fivetran, which we were already using in other places internally at Apollo. Through testing, we estimated it would take about 30 days to ingest a 800GB collection. And even if we could solve performance, there were still countless drawbacks regarding secure connection from outside the VPC, the enormous bill due to volume, etc. We then spent some time to evaluate open-source tools like Meltano, Spark, etc. None of them were promising - their runtimes were all in the same ballpark.
You can’t have it all
The tests weren’t for nothing. At this point, we came to the realization that ingesting a lot of data quickly and without using too much of the resources was not really possible. We needed to cut one of the requirements - data volume, ingestion time and resources. We can’t reduce data volume, we can’t do anything useful with 30-day runtime, so we must find a way to have more resources for the ingestions. And funnily enough, us hammering the staging cluster brought the idea that if we spin up our own cluster for ingestions, we can configure it to be as big as we want, we would have the whole cluster to ourselves, and it wouldn’t event cost a 100th of the SaaS bills. The snapshots are taken bi-daily, so we just have to schedule the ingestions as close to the snapshot time as possible for the latest data.
With great power…
Comes the great responsibility to squeeze out every drop of it.
We started to look at Mongo’s tools and found mongoexport, which reads and dumps Mongo data into JSON or CSV. Initial numbers weren’t that great, pretty close to what we had evaluated before. We spent a bit of time in its source code (yay open-source!), and found out that it’s only sending 1 query per process. What if we want… 32 queries?
mongoexport has the skip option to skip a number of documents before exporting. We could fetch the total count and split it up between 32 processes. However, it turned out the query cursors still had to iterate through the skipped documents, so what we had were 32 processes iterating through the entire collection. We needed the cursors to only iterate through a chunk of the data efficiently and without overlaps. And that was the perfect use for indices. All of our collections are indexed on the _id column, so we can query for min and max of _id and split the range into 32 chunks.
At this point, it took us 4 hours to ingest the same 800GB collection that we had been testing against. We thought increasing the VMs size would reduce the runtime linearly, but it didn’t; 4 hours was the best we could get. It was great progress, but our biggest collection was 20TB and we still couldn’t make the 6-hour window with this.
Going unconventional
Bigger VMs not resulting in better performance meant that there was a bottleneck.
While spinning up our own ingestion clusters, we got to learn about Mongo clusters’s architecture. In short, a cluster has routers that route queries to the correct shards based on the sharding information stored in config servers. And each shard in a cluster is essentially a standalone MongoDB. At this point, our ingestion clusters looked almost like the diagram, minus the backup instances (because we have no use for them).
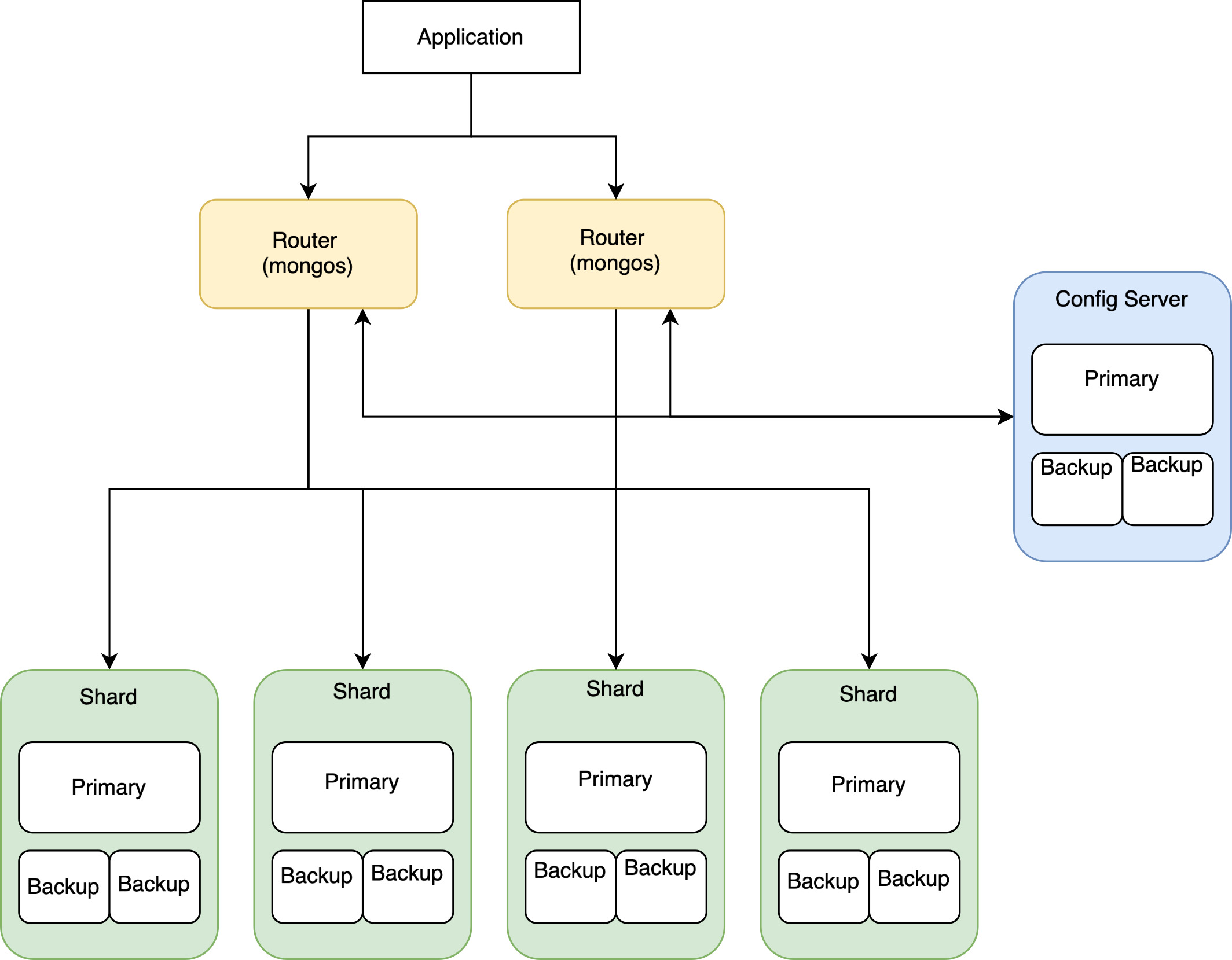
This setup works better for applications, where you usually query for a few documents at most. Here’s roughly how a Mongo cluster processes those queries.
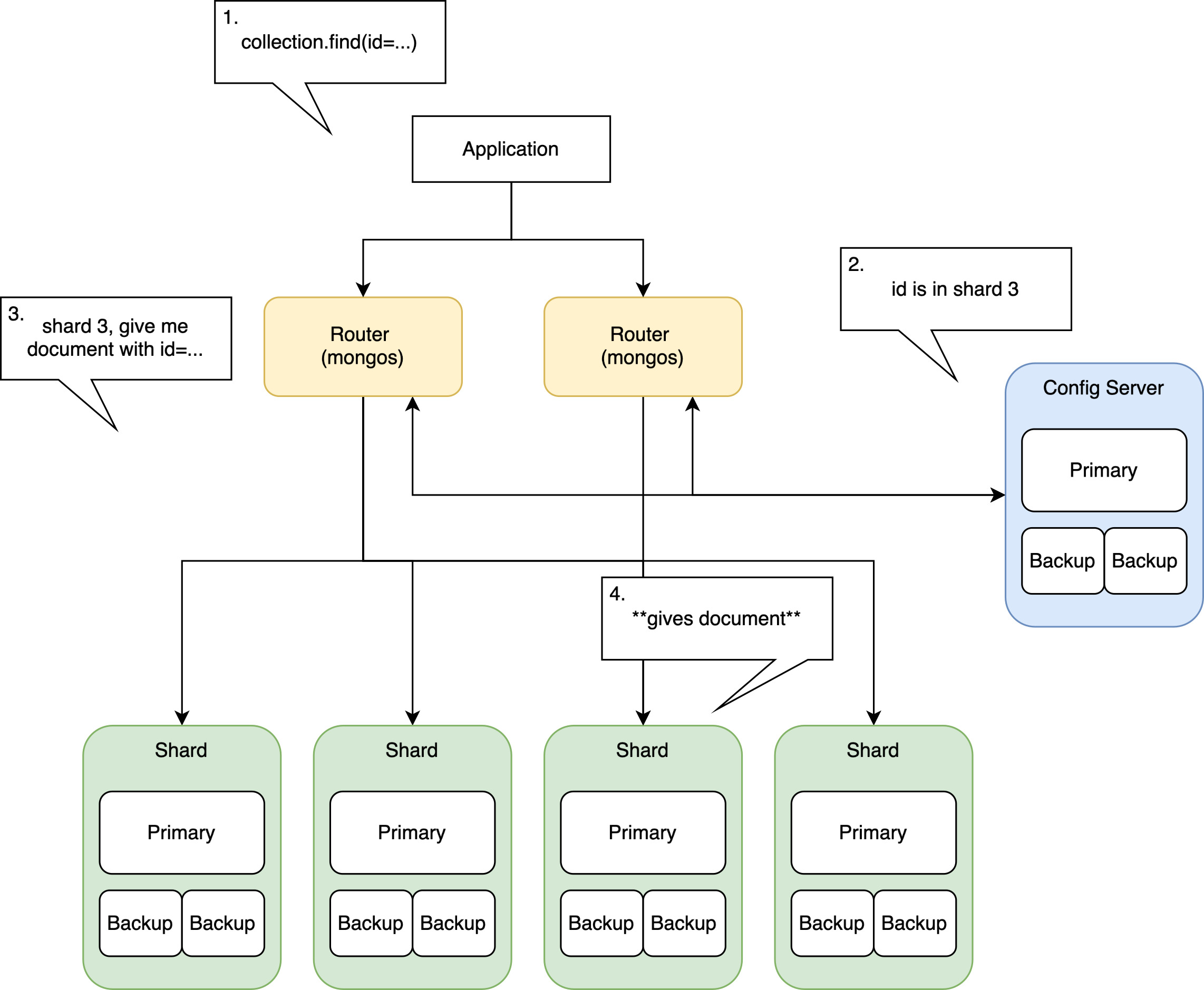
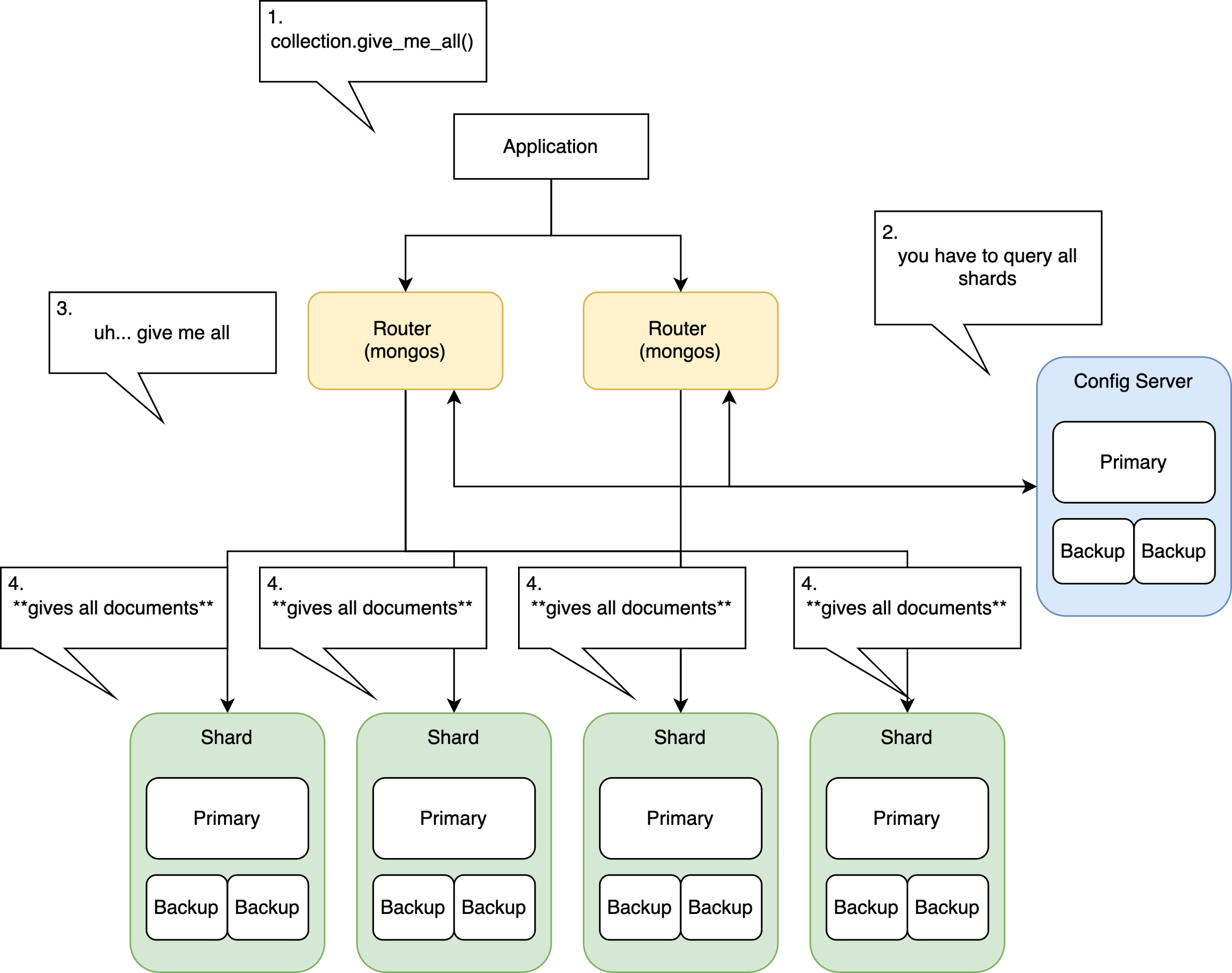
For our ingestion queries, it would go like this. And this was our bottleneck. We were moving a huge volume of data, yet there was a middle-man, and it was hitting 100% resource utilization while the shards weren’t even close.
We want all of the data, we know our queries are gonna hit all shards, so what’s the use for routers and config servers? And do we even need separate compute resource for our ingestion application? So we did some (excessive) trimming. We treated our shards as standalone MongoDBs, and queried directly against them.
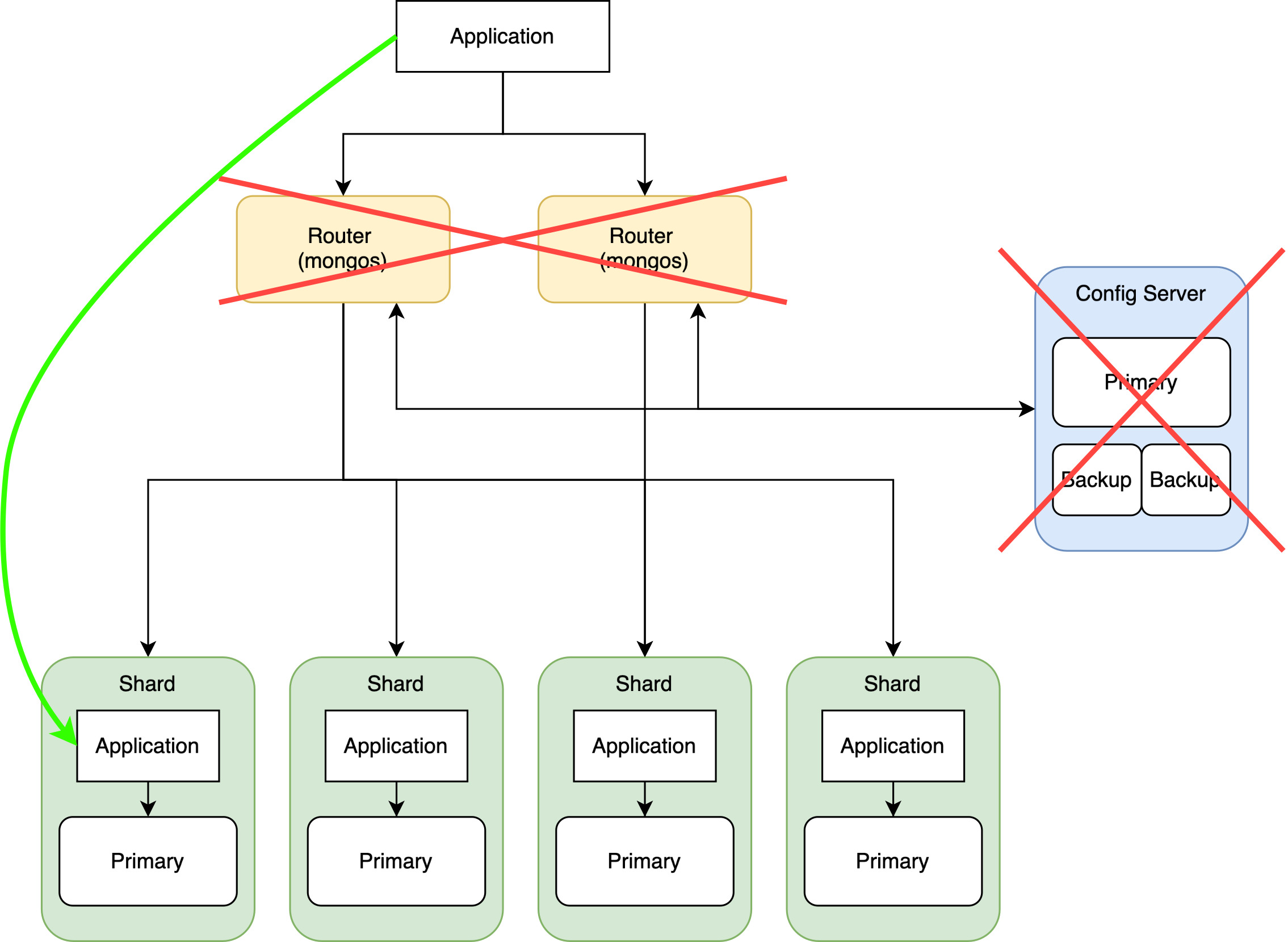
Now we have great power - all access to the CPUs, RAM and disk created for the ingestion “cluster”. We took the idea of running multiple mongoexport earlier and went crazy. How many mongoexport can a shard handle? 16? 32? … 128? Ok that was too much. We ended up with count(mongoexport) == count(cpus), and we were spinning up VMs with 32 vCPU. So comparing to earlier where we had 32 mongoexport running, we now have 256 (32 * 8 shards). The 800GB collection finished ingesting in 20-30 minutes 🎉 Even more importantly, this approach is scalable with bigger VMs, or more clusters. We never had trouble staying within the 6-hour limit, even for the 20TB collection.
I still remember the standup where I presented this result. I lost power at home that day and had to go to a coffee shop. I was beaming with so much pride and excitement that it felt like the whole shop was looking at me.
Final design and current state
The diagram below is taken directly from the design doc of this project. We recreate our Mongo VMs from the bi-daily snapshots. Then we directly run our ingestion process on these Mongo VMs. The ingestion process comprises of a number of mongoexport's that query and dump Mongo data to JSON files, which are then moved to GCS in a later step. All of this is orchestrated by Airflow.
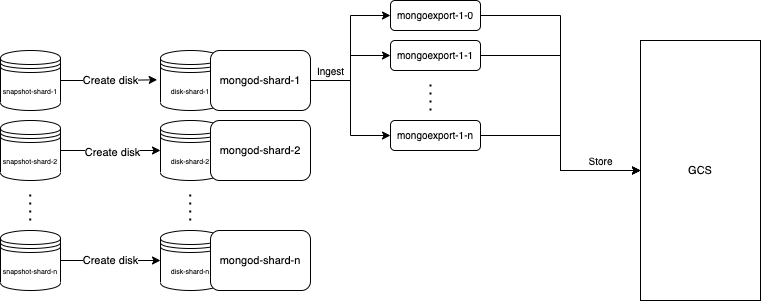
After a year of running this design, our ingestions were growing fast in demand and we needed to squeak out a bit more performance, so we wrote our own mongoexport, one that does as little data serialization as possible, and moves data from Mongo directly to GCS, instead of dumping files into disk. I would love to write about that project in a future post as well.
These snapshot ingestion pipelines have been running for 3 years and it doesn’t look like they will stop. We are currently ingesting about 100TB of Mongo data weekly, providing data for BI, AI/ML, Security, and more, while costing less than $2000/week. The pipelines have grown even bigger in impact because this very process is an important component in our Mongo CDC pipeline, where we use it to bootstrap data for near realtime ingestion.
🚀 .....and we are hiring!
Problem statements like these are in plenty at Apollo and we are betting big on AI for building products for our customers. Our engineering team thrives on solving complex problems, pushing the boundaries of what’s possible with data, and delivering cutting-edge solutions that drive "impact".
We are looking for smart engineers like you to join our "fully remote, globally distributed" team. Click here to apply now!