At Apollo.io, we're constantly working to improve our platform for Sales Development Representatives (SDRs) across various organizations. One common challenge our users face is managing the overwhelming volume of email responses they receive daily. SDRs often struggle to quickly identify and prioritize important replies amidst a sea of out-of-office messages, automated response, and other low-priority emails.
To address this, we developed an Email Reply Classification system. This system aims to automatically categorize incoming emails into predefined classes such as 'Out of Office', 'Unsubscribe', 'Willing to meet', 'Follow up question', etc. By doing so, we help SDRs focus their time and energy on the most promising leads and important conversations.
Our goal was to create a system that could accurately classify email replies at a scale of around 1 million per day in real-time, integrating seamlessly with our existing platform. This post outlines the technical challenges we faced in building this system, the solutions we implemented, including our data preparation strategies, and the model selection process.
🥷 Technical Challenges
The primary challenges we faced in developing this system were:
- Selecting an appropriate model that balances accuracy and speed for real-time classification.
- Creating a large, high-quality labeled dataset for training.
- Designing a scalable architecture to handle high email volumes.
- Ensuring the system adapts to evolving email communication patterns.
⛏️ Model Selection and Training
Selecting the optimal model was critical for the success of our system. We evaluated a range of options, including fine-tuning Large Language Models (LLMs), Transformer-based models like BERT, and lightweight models such as FastText. While LLMs demonstrated good accuracy with a smaller labeled dataset, the associated costs and latency at our required scale posed a significant hindrance to their practical implementation. Transformer-based models like BERT offered a middle ground in terms of performance but still presented similar scalability issues, particularly concerning latency.
Ultimately, we chose FastText as our classification model. FastText's lightweight nature offered an optimal balance between accuracy and inference speed, critical for our high-volume, real-time classification needs. Its efficiency in both training and inference made it well-suited for our large-scale deployment. However, this came with its challenge: FastText requires a larger high-quality labeled dataset to achieve high accuracy compared to LLMs or BERT. To address this, we developed strategies for efficiently creating a sizable, quality labeled dataset.
👩🏫 Semi-Supervised Learning Approach
We implemented a semi-supervised learning technique to expand our labeled dataset:
- Initial Labeling: We manually labeled a small subset of emails to create a seed dataset.
- Teacher Model Training: We fine-tuned a large language model on this initial dataset. This fine-tuned LLM became our "teacher" model.
- Pseudo-Labeling: The teacher model then predicted labels for a much larger set of unlabeled emails. It's like having a smart teaching assistant grade papers for you.
- Dataset Expansion: We only kept the high-confidence predictions—the ones where our teacher model was really sure about its answers. These high-confidence predictions became our "pseudo-labels", expanding our labeled dataset significantly.
- Iterative Refinement: We then trained our FastText model on this larger dataset. It's like the student learning from both the teacher and the teaching assistant's work. We repeated this process a few times, each iteration improving the dataset size and our model's performance.
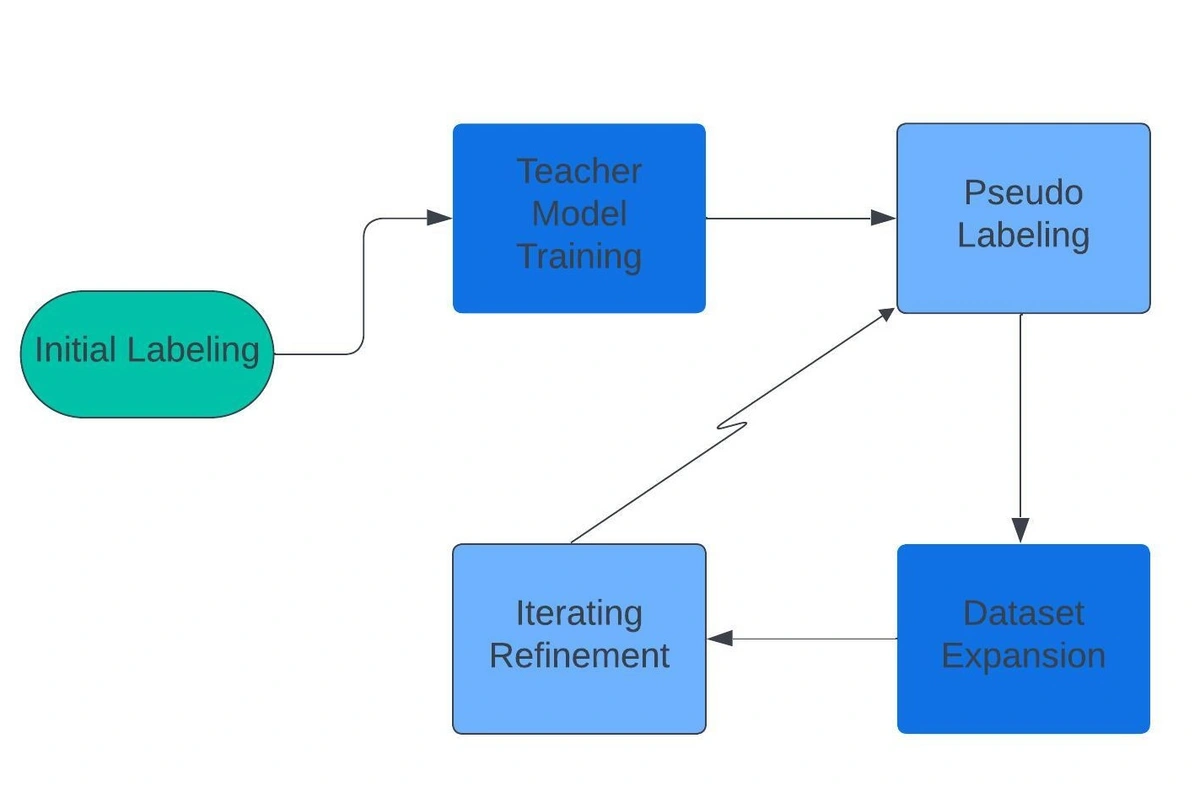
This approach allowed us to efficiently bootstrap a sizeable labeled dataset while minimizing manual labeling effort. In addition to semi-supervised learning, we also employed other data augmentation techniques such as back-translation to enhance our dataset's diversity further and improve our model's robustness to variations in phrasing.
Our training process involves:
- Partitioning our large dataset into training, validation, and test sets.
- Model Training and Hyperparameter Tuning.
- Performance Evaluation: Utilizing metrics including accuracy, precision, recall, and F1-score, tailored to the specific requirements of different email categories.
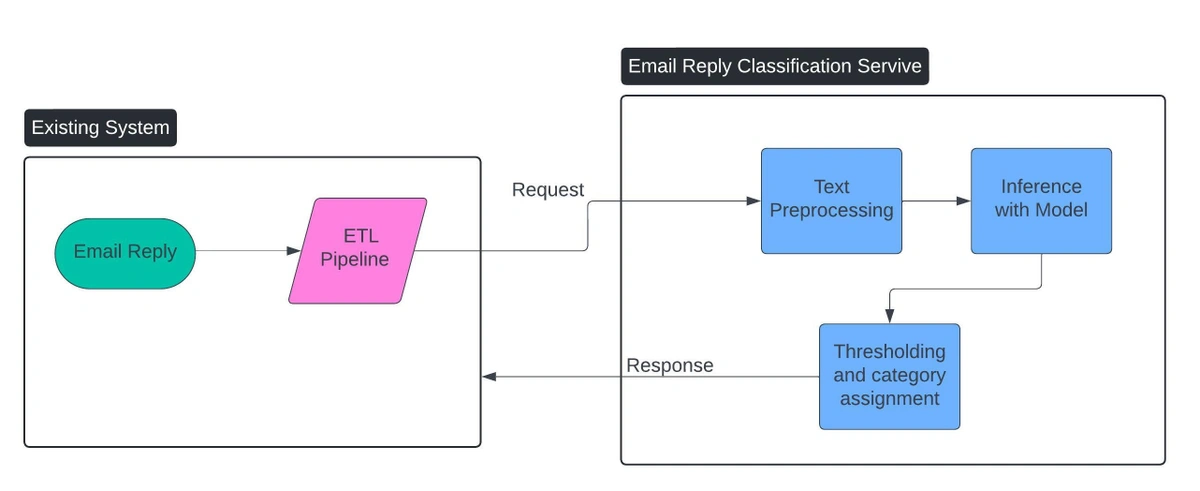
🛠️ System Architecture and Deployment
We created a robust and scalable architecture to handle the high volume and speed required for real-time email classification.
- Microservices: By adopting a microservices-based approach, we implemented a real-time processing pipeline that allows immediate classification of incoming email replies.
- Cloud Deployment Using Kubernetes: We deployed the system on Google Cloud Platform (GCP), utilizing its managed Kubernetes service for orchestration and auto-scaling. This setup enables us to manage peak loads and maintain high availability efficiently.
- Service Integration: We integrated our classification service with existing applications through RESTful APIs.
- Continuous Monitoring: To ensure reliability, we implemented continuous monitoring to track system performance, detect issues, and trigger alerts for any misclassifications or system errors.
💪 Results and Performance
After rigorous training and optimization, our Email Reply Classification system has achieved impressive performance metrics on our test set.
- Overall, the system demonstrates an accuracy of 90% across all categories.
- Notably, for the 'Out of Office' (OOO) category, we achieved a precision of over 99%, ensuring that when our system identifies an OOO reply, it's "almost" always correct.
- Our system maintains a high recall of over 90% for the critical' Willing to Meet' category, meaning we rarely miss potential meeting opportunities.
📜 Conclusion
Our Email Reply Classification system is helping our users manage their inboxes more efficiently, allowing SDRs to focus on the most important and promising communications. We continue to refine and improve this system based on user feedback and performance metrics. As email communication patterns evolve, so too will our classification system, ensuring that Apollo.io users always have access to the most effective tools for managing their email workflows.
🚀 We are hiring!
Problem statements like these are in plenty at Apollo and we are betting big on AI for building products for our customers. Our engineering team thrives on solving complex problems, pushing the boundaries of what’s possible with data, and delivering cutting-edge solutions that drive "impact".
We are looking for smart engineers like you to join our "fully remote, globally distributed" team. Click here to apply now!