In late 2024, we set out to reimagine how Apollo delivers enriched data through third-party vendors. The result: a modular, rate-limit-respecting orchestration engine we call Waterfall.
In under 9 weeks, we shipped the MVP and soon after that, it was a full product with pricing, telemetry, vendor observability, and robust failover mechanism. This is the story of how we did it—our architecture, learnings, and how we scaled from a prototype to a production system handling thousands of jobs per day.
Why We Built Waterfall
Enriching customer data, particularly contact data around email and phone information, is core to Apollo's value proposition. While Apollo has a rich trove of data that can be accessed to gain valuable information about potential prospects, gaps do exist. A popular mechanism for maximizing data accuracy and data coverage is the waterfall enrichment. Waterfall enrichments allow users to access data from multiple third-party vendors while validating the data for accuracy.
What is Waterfall?
Waterfall enrichments allow users to access data from multiple third-party vendors while validating the data for accuracy. In Waterfall enrichment, the user specifies which vendors they want to use to retrieve data and which vendor they want to use to validate the results. When an enrichment occurs, the enrichment retrieves data from the list of vendors in a sequenced order until it receives a validated result. Once it gets a validated result, it stops the waterfall and applies the results. Without Waterfall enrichment, customers would have to pay multiple vendors for the same data. With Waterfall, customers only ask vendors for the data they need. And thus, it is an efficient process of gathering data in a way that maximizes coverage and accuracy while minimizing cost.
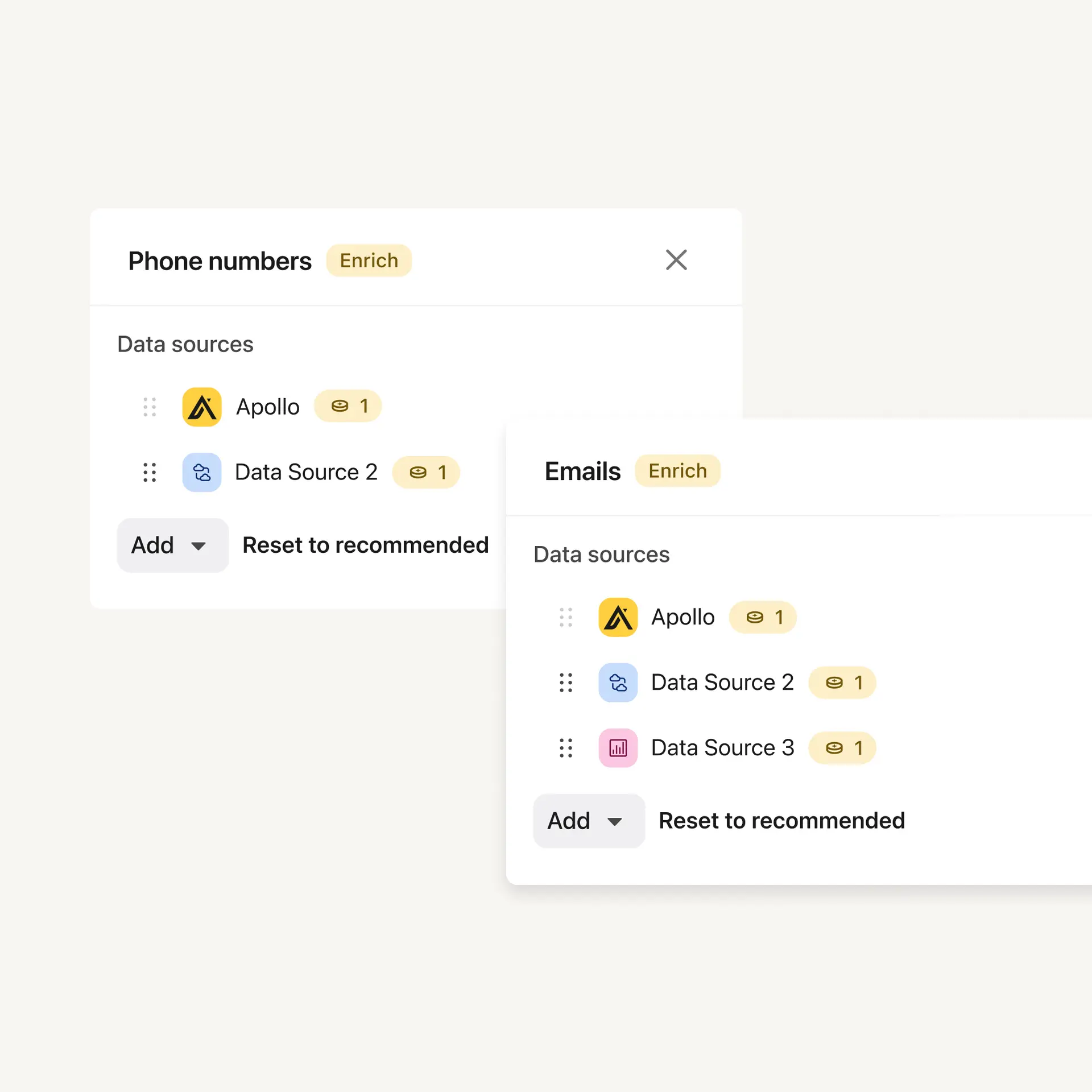
Architecture Overview
The core waterfall engine is quite simple. The engine needs a list of vendors along with the input parameters that the vendors need to resolve the request. For contacts, this is usually first name, last name, and company. The waterfall engine iterates through the list of vendors, passes the results to the validator and decides if it should continue.
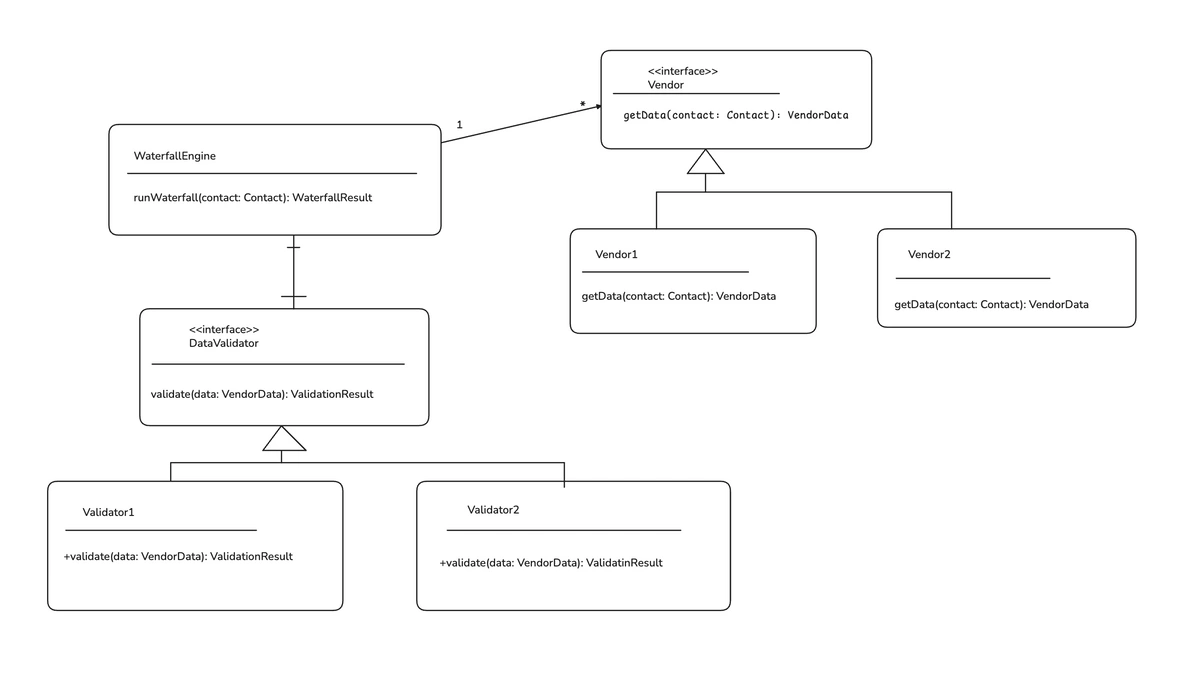
That’s a standard abstraction for the Waterfall Engine. It encapsulate the variation for calling vendors and validators behind a common interface.
Psuedo-Code:
class WaterfallEngine:
__init__(self, vendors: Vendor[], validator: Validator):
self.vendors = vendors
self.validator = validator
def run_waterfall(self, contact: Contact): WaterfallResult:
for vendor in self.vendors
vendor_result = vendor.getData(contact)
validation_result = self.validator.validate(vendor_result)
if self.shouldContinue(vendorResult, validation_result):
continue
return new WaterfallResult(vendor_result, validation_result)
return WaterfallResult::not_found()
This pseudo-code captures the core logic behind a Waterfall Enrichment, but of course if it were that simple we wouldn’t write this blog! The complexity of the Waterfall product comes from a few key areas.
- 🔧 Configurability - Customers are given a host of options to configure what vendors they want to call and how to call them.
- 🎨 User Experience - Customers want to know status of their Waterfall Enrichments. They also want to know where their data came from and how much it cost. This requires changes to the schema and a host of UI changes.
- 🔌 Vendor integration - Each vendor requires its own integrations, and they can present different behavior and failure modes. The Waterfall Enrichment must deal with all of this.
- 📈 Scalability - The pseudo-code enriches one contact. The Waterfall product needs to enrich tens of thousands of contacts per request. This requires an async architecture that comes with an array of additional complexities
- 🔄 Reliability - It's challenging to write reliable systems in any environment. However Waterfall involves the integration of multiple systems, many of which we don't control. We have to build a system that assumes every step can and will fail and deal with the failures.
- ⏱️ Rate-Limiting on Vendor End - Vendors don't play by the same rules. Some reset every second, others per minute, and a few don't document their rate limits at all.
Waterfall in 9 weeks
Given the enormity of this task, how did we deliver the Waterfall MVP in just nine weeks? The answer is to simplify the task to its core components. Many of these aspects are not required for MVP. For example we don’t need scalability when we have less than a hundred users and we only allow them to enrich up to 25 contacts at time. We don’t need the product to be so reliable it handles every fail condition for MVP. What we DO need is a core product with a functioning user experience that can perform the task at a small scale. This allows us to deliver quickly and gather customer feedback in a timely manner.
The team got to work with a sense of urgency and focus to get the minimum viable product delivered by working backwards from our target date. The requirements were focused on the bare minimum. The team identified shortcuts that would allow us to deliver quickly. For example, the narrow set of initial third-party data vendor configurations were hard-coded, saving us valuable time.
However, knowing what to build in these scenarios is important. If you don’t have a solid engineering design to work off of, your MVP is likely to morph into a festering mass of tech debt. To alleviate this risk, the Engineering team dedicated the first two weeks to writing a comprehensive Engineering Design Doc. This set the stage for the Waterfall system, and the core tenets of the design are still in place today.
By the end of the nine weeks the Waterfall team delivered a functioning MVP and put it in the hands of a select group of beta testers.
Tackling the Complexity - Third Party Vendor Integrations
At their core, most vendors do the same thing. They provide a set of REST APIs that we can call to get data for the Waterfall Enrichment. To integrate a vendor we store the key elements of a vendor integration in a separate file. Each entry in the file defines an endpoint exposed by the vendor, how it expects the data to be passed in and the supported rate limit for that endpoint. We can use that data to reduce the amount of code needed for each vendor implementation, and we can make adjustments quickly when needed.
📏 Vendor Rate Limiting
As a consumer of external APIs we have an obligation to be good citizen users and ensure that we do not overburden our vendors with too many calls. There are a few ways to tackle this. We can make calls until a vendor hopefully responds with a rate limit code and the time we have to wait between calls, or we can track our call rate ourselves and implement the proper throttles. We chose the latter.
By throttling our own calls we gain several advantages. We no longer need to rely on our vendors properly telling us if we violated rate limits. We don’t have worry about flooding vendors with a sudden influx of in flight requests, and we don’t have to rely on vendors complying to standard rate limiting headers. This allows us to onboard new vendors more easily even if they don’t comply with the standard headers.
Given that our Waterfall requests run in parallel SideKiq workers, we needed a way to share call rate state. To do this we implemented a leaky bucket algorithm where we store the bucket state in Redis. Using Lua we can apply the leaky bucket algorithm and ensure that we don’t run into race conditions across workers.
📟 Vendor Visibility - Leveraging QPoint
As waterfall scales, more failures are bound to crop up. This is especially true when it comes to calling third-party vendors. We need to have a detailed view of what is happening when we call a vendor at the connection level. For this, we employed QPoint.
💡 QPoint uses lightweight eBPF agents to give users a full view into their service traffic. This was a perfect fit for our use case, and in many cases we have been able to root cause an integration with a vendor simply by looking at our QPoint dashboard.
Scaling Waterfall from MVP to Production
As we built out the MVP we were able to implement an async solution for the Waterfall execution engine by leveraging an existing workflow library that ran as a SideKiq worker. This allowed to easily track state as we ran through the waterfall. However with such an aggressive timeline some challenging issues arose.
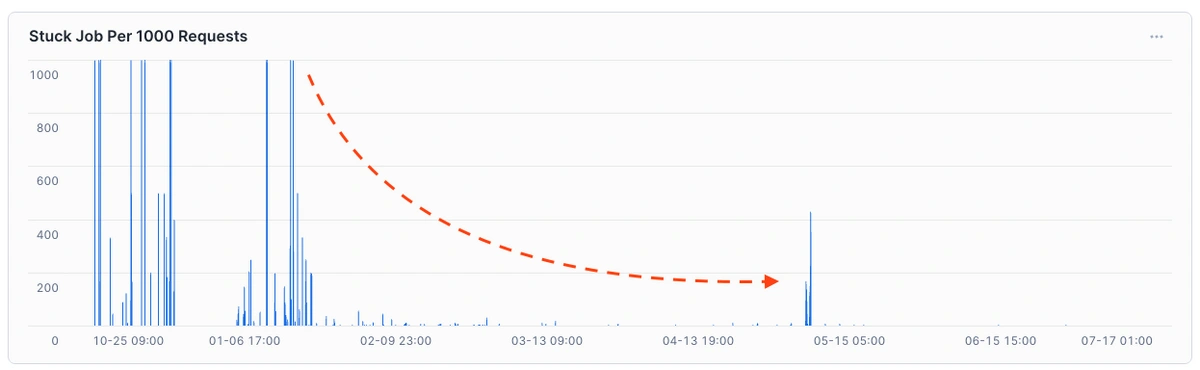
As previously mentioned, Waterfall initially supported enrichments for only 25 contacts per job—but even those jobs were unreliable. Many stalled while waiting on internal email and phone enrichment services. These reliability issues would only worsen at scale, so addressing them was our first priority.
Fixing Reliability
A large percentage of jobs were getting stuck due to how we integrated with our own email and phone enrichment systems. In this post, we’ll focus on the email enrichment piece.
Apollo’s internal enrichment data is rich, but integrating with our asynchronous Email Verification Request (EVR) system posed challenges. EVR supports robust scaling mechanisms that include tenant fairness and priority lanes but was designed with a “fire-and-forget” approach, making it hard to synchronize data. Ironically, our own system proved to be the hardest to work with.
Our initial integration simply watched for side effects—polling contact state to infer completion. This was fragile and expanded the amount of shared mutable state we had to manage.
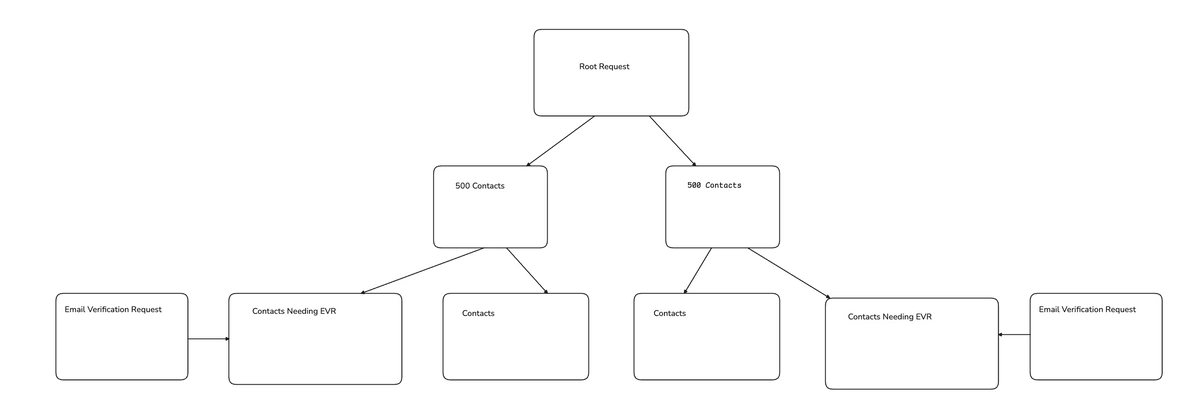
The better solution was to explicitly wait for the EVR job to complete before continuing the Waterfall. To manage these dependencies cleanly, we adopted a Directed Acyclic Graph (DAG) model.
Moving to a DAG
DAGs let us define task dependencies explicitly. For example, we could model the dependency on EVR directly:
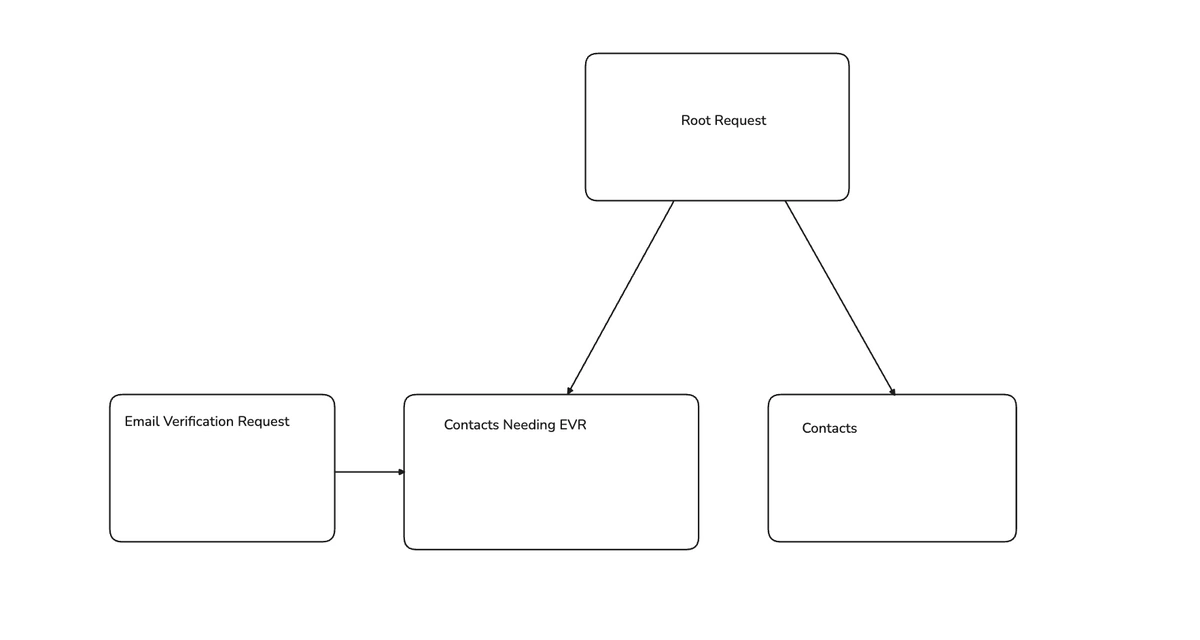
Adopting this pattern dramatically reduced the number of stuck jobs.
Scaling Job Size
With reliability in place, we turned to scaling job size—from 25 to 5,000 contacts per job.
To do this, we extended the DAG.
For example, enriching 1,000 contacts could be split into two intermediate layers of 500-contact batches, which run in parallel. Structurally, this was simple.
Measuring Performance
To truly scale, we needed visibility. We focused on key metrics:
- Throughput: Contacts enriched per minute
- Latency: Time per job (segmented by batch size)
- Error Rate: Should stay flat as load increases
- Stage-Level Timings: Time spent in each part of the Waterfall
This breakdown let us pinpoint bottlenecks. The run_waterfall stage—where we call third-party vendors—was the slowest. Not surprising, since it's where we have the least control.
Evaluating Vendors
Scaling isn’t just about speed—it’s also about vendor performance. For each vendor, we monitor:
- Latency
- Fill rate
- Verification rate
- Rate limits
Rate limits quickly became the biggest bottleneck. Once hit, calls queue up, degrading performance as work accumulates faster than it can be processed.
To avoid this, we track how much time is spent making calls vs waiting on rate limits. When waiting dominates, we proactively reroute traffic or time out the vendor and move on to the next one in the waterfall.
We also forecast future traffic based on current transactions per second. When needed, we request higher rate limits from vendors, who are typically happy to accommodate, since they’re paid per call.
Throttling Responsibly
Internally, we enforce rate limits proactively. This keeps us in good standing with vendors and lets us estimate how long a request would need to wait. If it’s too long, we can skip the call entirely and proceed with the next vendor, keeping user experience fast and responsive.
Scaling Results
By taking a thoughtful metrics-driven approach to scaling, the Waterfall team has successfully scaled a product that started with less than 100 contacts enriched a day to more than 500,000 contacts enriched per day. As we scale up the product further, we’re confident in its ability to handle the anticipated load.
What does all of this work mean for our customers? It means more data and higher-quality data. Initial beta results show a 12–15% improvement in email fill rates and roughly a 30% reduction in bounce rates. By using Waterfall, Apollo’s customers can reliably reach to more people faster, empowering them to get the most out of their Go To Market efforts.
🔮 Looking Ahead - Join Us At Apollo!
Waterfall started as a bold idea to fix enrichment gaps and became a production system enriching 500K+ contacts daily and growing. It’s proof that when Apollo teams move fast and think big, we don’t just ship features — we redefine what’s possible for our customers and build a strong competitive advantage at lightning speed.
We would love for smart engineers like you to join our "fully remote, globally distributed" team. Click here to apply now!