Data is at the core of Apollo’s business. The company started as a sales prospecting data vendor before becoming the all-in-one sales platform. Sales prospecting continues to be the one of the most fundamental and important parts of our business portfolio. Building and maintaining such a big data business comes with its own set of challenges and requires a robust and scalable data platform. Additionally, with Apollo’s focus on Artificial Intelligence (AI) based Sales, we also need an equally powerful machine learning (ML) platform to continue to build state-of-the-art AI products. In this post, we will cover the evolution of our Data and ML Platform that has allowed us to become one of the most well-known brands in the all-in-one sales technology space.
How it all started
Since the company’s inception, our infrastructure to support prospecting / leads data as a product has been quite robust and has evolved continuously. We ingest data from multiple external and internal sources, and process it to generate arguably the highest quality people and company data. Our millions of customers use this data in different ways which generates millions of usage patterns that allow us to continuously refine our product and generate in-depth insights. Until a few years ago, we had a barebones data warehouse where we used to ingest only our CRM data to generate minimal reports. All product usage analytics was done in Amplitude. Our transactional data and analytical data were persisted in different storage systems which blocked us from generating insights using a combination of these datasets.
As our Data Platform team grew, we invested more in bringing all our internal data sources together, eventually building out our centralized Data and ML Platform.

Our original bare bones Data Platform architecture
Proposed Architecture
The Data Platform team set a goal to build a centralized platform that stores, manages, processes, and analyzes all our data while supporting the development and deployment of machine learning models. This unified platform would empower every team within Apollo to harness the power of data and machine learning. We started with a high level architecture proposal and then broke it down into several phases. Having built out similar platforms in our previous companies, our team was confident of the success of this project, but we faced unique technical challenges that forced us to come up with multiple creative solutions to achieve what we wanted. The diagram below shows our proposed architecture for the Data and ML Platform.
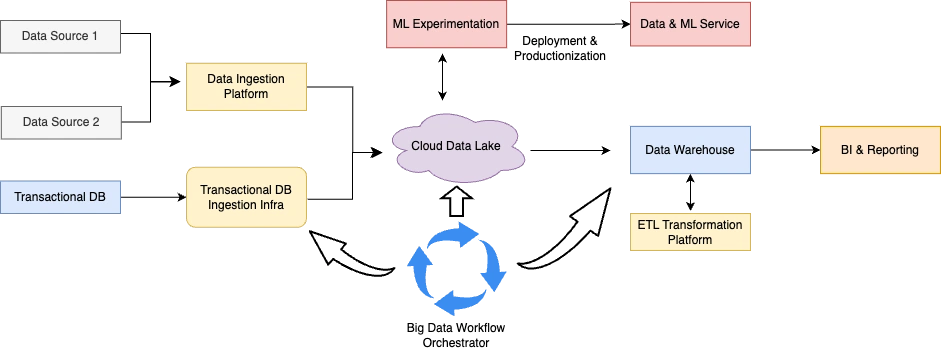
Proposed high level functional architecture of the Data & ML Platform
Phased Development
Building the end-to-end platform was a huge undertaking and would take us months to deliver. We divided the development into multiple phases, where the outcome of each phase would be a useful deliverable that our teams could start consuming.
Phase 0 - Data Warehouse & Reporting for Revenue Operations
Our first phase involved setting up the foundation of the Data & ML Platform. The Revenue Operations team played a pivotal role by establishing a Snowflake-based data warehouse and Looker-based reporting platform. This phase was crucial as it provided the essential infrastructure for data warehousing and reporting, which other teams could later build upon.
Phase 1 - People & Company Data in the Data Platform
In Phase 1, we tackled the challenge of migrating our People and Company data from our transactional database (MongoDB) to our data warehouse (Snowflake). This transition was a significant milestone, as it allowed us to move critical data collections into the Data Platform. Using tools like dbt, we performed necessary transformations within Snowflake, creating a gold standard dataset that would serve as the basis for our analytics and reporting.
Phase 2 - Scaling Data Ingestion from MongoDB to Snowflake
As our data needs grew, we expanded our data ingestion capabilities to handle larger datasets from MongoDB. This scaling process ensured that we could efficiently bring in vast volumes of data into our platform, setting the stage for more extensive analytics and machine learning activities. This step was particularly challenging since our Mongo setup was not compatible with off-the-shelf ETL tools that could ingest data directly from MongoDB to GCS or Snowflake. We had to build a custom infrastructure to enable this ingestion. We will discuss this infrastructure later in this post.
Phase 3 - Creating L1 and L2 Metrics Dashboards in Looker
To empower data-driven decision-making, we created essential L1 and L2 metrics dashboards in Looker. L1 and L2 metrics refer to our product data taxonomy that is divided across use-cases and features. These metrics include things like activation, retention, adoption, etc. for each use-case and feature. These dashboards provided teams with valuable insights and actionable data, further demonstrating the platform's impact on our operations.
Phase 4 - Setting Up a centralized Data Lake
While we did not build an official Data Lake, we did start using Google Cloud Storage (GCS) as our centralized store for all our datasets. Additionally, we integrated GCS with Databricks which expanded our data storage and processing capabilities. GCS became the central repository for diverse data types, enabling teams to explore non-SQL-based analytics through Databricks' powerful notebook interface.
Phase 5 - Setting up Airflow for workflow orchestration
Integration with Airflow marked a significant milestone in our ability to orchestrate complex data workflows. We integrated Airflow with Apache Spark that allowed us to process huge amount of data in batch workflows.
Phase 6 - Setting Up the ML Experimentation Platform
Machine learning experimentation was a key focus of our project. We established a robust ML experimentation platform that provided a Notebook interface connected to our Data Lake in GCS. The initial version of it was powered by Databricks. This platform offered powerful features, including Spark-based processing, on-demand compute resources, multi-language support, experiment tracking, code versioning, and code review capabilities.
Phase 7 - Setting Up the Data & ML Service
For ML model deployment, we built our custom Data & ML Service. This is a FastAPI based Python service and is used to host and serve machine learning models and datasets for various use-cases, including Search, Recommendations, and Conversations Intelligence.
The Complete Technical Architecture
It took us about 5 months to complete all the phases of the data and machine learning platform. During this time, we continued to provide iterative value to the business through the intermediate components at each phase. The final end-to-end architecture of the platform looked like the below.
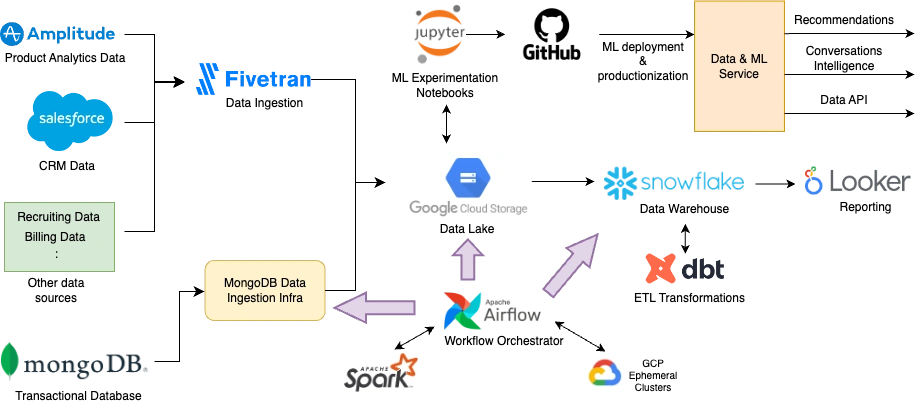
Comprehensive technical architecture of the completed Data and ML Platform
Challenges Faced
Building this behemoth of a platform was not a smooth sail by any means. We faced several challenges on our way.
- Out of the box solutions did not work for data ingestion from MongoDB: The way our MongoDB infrastructure was set up made it incompatible with the out-of-the-box data ingestion platforms like Fivetran and Debezium. We spent at least a month in trying out different approaches to ingest data from MongoDB to GCS (Google Cloud Storage) in our unique setup but nothing worked. Eventually, we built a custom infrastructure that would run a weekly scheduled job in Airflow to spin up a duplicate MongoDB cluster in GCP (Google Cloud Platform), load all data from production MongoDB backup disks, and finally run mongoexport on this cluster to export this data to GCS. We will cover this topic in detail one of our future blog posts.
- PII data had to be masked: Since we were moving data from our production transactional database to our data warehouse, we needed to mask the PII (Personally Identifiable Information) data before moving it into the data warehouse. We created ETL jobs in DBT and updated the schema of the data in data warehouse to redact PII fields completely.
- Cost to build the whole platform was high: Before we could even start building this platform, we came up with some high level estimates of what it would cost annually to keep this platform running. This cost was obviously very high so the team paid close attention to optimizing costs wherever possible while developing this platform. For e.g., we minimized our usage of Databricks and kept its access restricted to only the high priority use-cases. We also continuously optimized the jobs that read data from MongoDB to reduce the cost of running them.
- MongoDB data could only be ingested on a weekly basis: The first version of the MongoDB ingestion infrastructure ran weekly jobs that would take north of 10 hours to ingest all MongoDB collections into GCS. Therefore, we decided to run these jobs on a weekly basis. This impacted our BI (Business Intelligence) reporting since the business reports could only be refreshed weekly. Later, we optimized these jobs and some of them are now running on a daily basis, while some others can even be run multiple times per day.
How is the platform evolving?
The completion of Apollo's Data and Machine Learning Platform was a significant milestone for our organization. This unified platform empowers every team within Apollo to leverage power of data and machine learning for better decision-making and improve the customer experiences. However, this version of the platform lacked capabilities for real-time (or near realtime) data ingestion and prevented machine learning use-cases that relied a more timely availability of data. To address this, team built real-time data ingestion infra using Kafka. This also allowed our product engineering teams to subscribe to customer behavioural events and run operations in response to them, in real-time. As we move forward, our commitment to excellence, security, and innovation will continue to drive us to new heights in data-driven success.