AI Tagging : From Feedback To Actions
Written by Mohit Kumath
August 26, 2025
Hearing Our Customers at Scale
This article was co-authored by Raja Jamwal and Mohit; leadership support from Utsav Kesharwani.
In today's fast-moving business world, staying relevant comes down to understanding our customers. At Apollo, we prioritized capturing Voice of Customer (VOC) data at scale. This meant going beyond the basic collection of customer feedback to tracking Customer Interaction Rate (CIR) metrics across our teams and product features. This shift helped us gain a clear view of escalation trends and recurring customer complaints over time.
Special thanks to Raja Jamwal for collaborating on bringing this story to life!
🪫 The Manual Tagging Bottleneck
Traditionally, our Customer Success Management (CSM) team handled customer conversations on Intercom. CSMs manually tagged these conversations using a Three-level Hierarchical Taxonomy to gain insights. This taxonomy broke down product surfaces into categories (Level 1, e.g., 'Engage'), features (Level 2, e.g., 'Engage > Email'), and core functionalities (Level 3, e.g., 'Engage > Email > Settings'). When a customer escalated an issue, CSMs would reference this taxonomy sheet to apply the relevant tags to the conversation.
This manual tagging was crucial because these tags fed into our analytics platform, which measures each internal product squad's performance against customer needs (CIR metrics). Without accurate tags, we couldn't generate meaningful trends or extract valuable insights.
💬 “Only a fraction of our 1000s of customer conversations get tagged, and even then, the data is messy and inconsistent. We were missing the real customer story.”
And this process quickly became problematic as our customer interactions scaled:
- Low Coverage: Only a small portion of our approximately 25,000 monthly Intercom conversations were being manually tagged by CSMs. This meant we were missing out on a massive amount of valuable customer data and insights.
- Inaccuracy: Manual tagging is inherently prone to human error and inconsistencies in understanding. With over 248 possible tags, many were unused or misapplied, leading to diluted or misleading data.
- Operational Challenges: The sheer volume of tags, the lack of sufficient training data for automated models, and the constant evolution of our product features meant that manual tag maintenance and application struggled to keep pace. There was a critical need to maximize tagging coverage while ensuring high accuracy.
🧠 Automating Customer Feedback with AI
Our solution aimed to automate the tagging process entirely, focusing on improving both the volume of tagged conversations and the accuracy of the tags, all while adhering to the existing CSM-defined taxonomy.
Architecture and LLM Integration
The core of our technical solution involves a robust data pipeline and sophisticated use of Large Language Models (LLMs):
- Data Ingestion: Intercom conversations are first synced to our Snowflake data warehouse via Fivetran, acting as a Change Data Capture (CDC) pipeline.
- Automated Processing: An Airflow DAG (Directed Acyclic Graph) picks up these newly synced conversations from Snowflake.
- LLM Interaction (DAPI): The Airflow DAG then calls a custom DAPI (Data API), which has a LangGraph-based pipeline with LangSmith observability, where the magic happens. This API makes calls to the LLM model for automated tagging. We evaluated and benchmarked multiple LLM Models for accuracy.
- Handling Long Conversations: A significant challenge was the token limits of LLMs. Many Intercom conversations are quite lengthy and exceed these limits. Our solution implements a multi-pass summarization strategy. The system chunks long conversations, summarizes each chunk, and then refines these summaries to create a concise overview focused specifically on the customer's complaint or problem. This ensures the LLM receives the most relevant information for tagging.
- Contextual Tagging with YAML: The existing three-level taxonomy sheet, maintained by the CSM team, was converted into a YAML-based format. This YAML provides the LLM with structured context for each tag, including its definition, what it covers, common FAQs, and even fallback support.
- Few-Shot Learning: To enhance accuracy, the LLM is provided with few-shot examples—sample conversations from a labelled, golden dataset that illustrate the kind of discussions that apply to specific tags. This helps the model understand the nuances of each tag.
- Multi-Tag Prediction and Confidence: Customer conversations often touch on multiple features. Our system is designed to suggest between 1 and 3 tags per conversation, requiring a high confidence score for each tag to ensure high precision.
- Output and Storage: The LLM produces a list of relevant tags and the reason for their applicability. These generated tags are then written back into a separate Snowflake table for preparing Business Intelligence (BI).

Overcoming Technical Hurdles
While developing this system, we encountered and addressed several technical challenges:
- Long Conversations: Many customer threads can be very lengthy, often spanning 20+ messages with screenshots, error messages, and configuration details. While GPT-4o supports a 128K-token context window, we intentionally split conversations into segments and recursively summarize.
- For example, a customer thread about email deliverability issues might span weeks of back-and-forth messages. We recursively summarize each segment, with every pass refining the content to focus on the customer’s core pain point. We then run a two-pass summarization to combine these chunk summaries into one coherent result.
- Tag Taxonomy Complexity: Our three-level hierarchy (Category → Feature → Function) demands precise context matching.
- Distinguishing between "Engage > Email > Settings" and "Engage > Email > Deliverability" requires a nuanced understanding. We load rich metadata from YAML and apply fuzzy matching to handle typos. This helps correctly tag conversations even when a CSM mentions "email deliverabliity" instead of "deliverability".
- Multi-Feature Conversations: Conversations often span multiple features, risking over- or under-tagging.
- A customer might discuss both Salesforce integration issues and email sequence problems in the same thread. We cap tags to 1–3 per conversation at ≥ 90% confidence and enforce output via a Pydantic TagList schema. This improves precision but may leave nuanced cases untagged if confidence falls below the threshold.
- Tagging Accuracy: To instill confidence in the AI model among stakeholders and CSMs, the system must generate accurate tags with clear visibility into the tagger's performance.
- When our model tags a conversation about "email bounce issues" with "Engage > Email > Deliverability" instead of "Engage > Email > Settings," we need to understand why and improve accordingly.
Data-Driven Validation
To instill confidence in the AI model's accuracy among stakeholders and CSMs, we established a rigorous benchmarking process:
- Golden Data Set (Human eval): We created a "golden data set" of many hundreds of sampled conversations that were manually labeled by 10-15 CSMs over the course of a week. This human-labeled data serves as our ground truth for evaluation.
- Benchmarking: An internal benchmarking program compares the AI-generated tags against this golden data set. It evaluates how many tags overlap, how many are missing, and other crucial metrics common in ML domains.
- Key Metrics: We track F1 scores, precision, and recall at each of the three taxonomy levels.
- Level 1 (Main Category): The AI model achieves an excellent Macro averaged F1 score of 0.81 (0.8091 Macro Precision, 0.868 Macro Recall). This indicates strong performance at a high level.
- Level 2 (Main Category + Feature) used for Team level CIR: Performance remains good with a Macro averaged F1 score of 0.70 (0.701 Macro Precision, 0.761 Macro Recall). Anything above 0.6 is generally considered ready for real-world tasks. Some teams even outperform at an F1 score > 0.90.
- Level 3 (Main Category + Feature + Functionality): The Macro F1 score drops to 0.50 (0.477 Macro Precision, 0.584 Macro Recall) at the functionality level.
The significant drop in accuracy at Level 3 was a key finding. We discovered that this was primarily due to ambiguous and conflicting context definitions within the taxonomy sheet itself.
The benchmarking program that we wrote is able to provide a drill-down investigation into the worst-performing tags and at which level they are under-performing. Using those benchmarking metrics, we can go back to the taxonomy sheet and incrementally improve it.
To improve accuracy further, especially at Level 3, our strategy is to:
- Identify Weak Areas: Use the benchmarking code to pinpoint the worst-performing tags and categories at each level.
- Refine Taxonomy Context: Work with CSMs to improve the definitions and provide clearer positive and negative examples in the product taxonomy definition. By improving the context for Level 3, the accuracy for Levels 1 and 2 automatically improves.
The Impact: Transforming Customer Insights and Product Development
🔮Bringing us closer to the “Truth”
The biggest win from our AI tagging system is clarity. For the first time, our teams have a complete and accurate view of what customers are saying—not just a small sample.
| Before AI | After AI |
|---|---|
| Only about 8000 customer conversations are manually tagged monthly | Over 37,000 conversations are automatically tagged monthly |
| The majority of feedback is unclassified | Nearly full coverage of customer feedback |
| Decisions based on incomplete and sometimes misleading data | Comprehensive view for better decision-making |
Product and support teams now have unprecedented visibility into customer pain points and feature requests. Instead of flying blind, they can spot trends early, measure progress over time, and prioritize the issues that matter most to customers.
The processed data is pushed to visualization dashboards, offering leadership and product teams detailed insights into Customer Interaction Rates (CIR) and issue progression for every feature and squad.
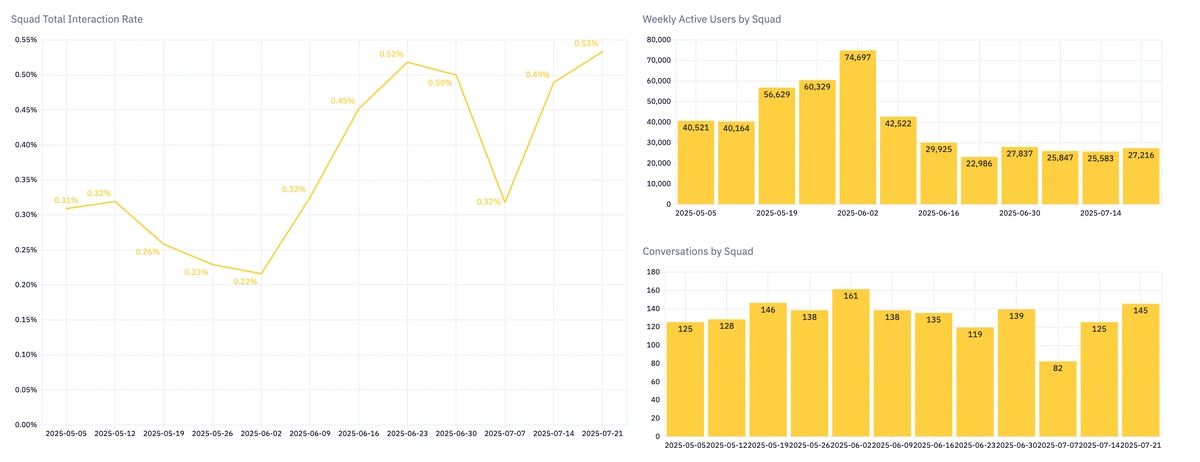
CIR dashboard
⏱️Saving enormous time
Before AI, our Customer Success Managers (CSMs) had to manually tag conversations while managing their other responsibilities. This limited them to classifying only a fraction of the 25,000+ monthly conversations, diverting valuable time that could have been spent directly helping customers.
With AI, that bottleneck has disappeared. The system now automatically tags over 37,000+ conversations every month, providing comprehensive coverage at a scale unattainable through any manual process.
📁Making us operationally efficient
Apollo now has real-time customer intelligence at a fraction of the cost, giving every team the clarity to act faster and smarter.
Real-time dashboards bring this to life: CIR metrics update automatically with complete, accurate tagging, allowing leaders to spot trends, track escalations, and drill into feature-specific pain points with confidence.
And because the system removes the burden of manual tagging, CSMs and PMs no longer spend hours classifying conversations—they can dedicate their time to analyzing insights, solving problems, and driving customer success.

🎯Providing accuracy at Scale
For context, our previous paid tagging approach achieved only 59% accuracy. Our testing of the AI against a carefully labeled dataset revealed compelling results:
- Categories (Level 1): ~81% accuracy
- Features within categories (Level 2): ~70% accuracy on average, with some teams exceeding 90%
- Detailed functions (Level 3): ~50%, primarily constrained by taxonomy clarity
This improved performance stems from enhanced structured context using YAML taxonomy, few-shot learning, and robust multi-pass summarization—and NOT from any single model innovation.
💰Saving money!
We’ve fully replaced the paid tagging tool with our in-house pipeline, which exceeds its performance, removes licensing constraints, and reduces ongoing costs while giving us complete control over privacy, iteration speed, and roadmap.
Processing tens of thousands of conversations with GPT-4o costs pennies compared to human labor, while maintaining consistency and scalability.
Rise of the AI Product Manager
Our system is designed to adapt as our product features evolve. New tags can be introduced by CSMs and the quality team directly into the existing Google Sheet taxonomy following its established format. The system consumes this updated YML, ensuring the AI tagger remains in sync with the latest product surfaces.
One of the most exciting future outcomes is the enablement of an "AI PM" capability - a concept that's revolutionizing how we plan to turn customer feedback into product improvements.
The days of customer insights languishing in feedback queues, struggling through prioritization bottlenecks, and facing lengthy implementation timelines are being challenged across the industry. With the above AI-powered approach, we aim to create a direct pipeline from customer voice to product enhancement. The AI tagger doesn’t just label conversations—it creates concise summaries that cut straight to the customer’s core issue. These summaries are organized by tags, making them easy to query and aggregate.
A product manager can, for example, instantly pull every insight related to “Salesforce Integration.” From there, the summaries can be passed into a larger LLM (like Gemini), which acts as an AI Product Manager—automatically generating PRD-like insights: the biggest issues, how often they occur, and even suggested solutions.
The result? Automated backlog building that’s faster, more accurate, and customer-driven. Product teams get real visibility into what matters most, and new PMs can ramp up in hours instead of weeks. Watch out as we double down on these "green shoots" and share here!
...join us! ✨
The AI gods would be proud—real-world problems, once impossible to solve at scale, are now being tackled head-on with AI. At Apollo, that future arrived yesterday!
You’ll be joining a global team of fantastic engineers who thrive in a fully remote environment—spread across continents, but connected through deep technical collaboration.
We’re scaling fast, expanding our engineering hubs worldwide, and exploring new frontiers in AI, usability, and platform performance. If you’re excited to shape the future of Apollo alongside world-class peers, come build with us.
Interested in joining our team? Check out our careers page!