How We Tamed Complex Queries Without Slowing Down the Universe
If you’ve ever built a search engine that supports custom scoring, you’re probably familiar with the “Latency Monster” that shows up as your scoring logic grows more complex. At Apollo, our users define intricate scoring criteria—“Give me +30 points if a contact has ≥3 email opens, +20 if they clicked on an email, +15 if they work in a specific industry,” etc.—and over time, these rules can balloon to dozens of filters in a single query.
But why would anyone need such custom scoring? In many domains—particularly sales, marketing, and lead management—not all documents are created equal. Some data points (like frequent email opens or clicks) might strongly correlate with a lead’s propensity to engage or buy; others (like the lead’s industry or job title) might only matter in certain contexts. By assigning weights to each signal, you can tailor the search results to surface the highest-value leads first.
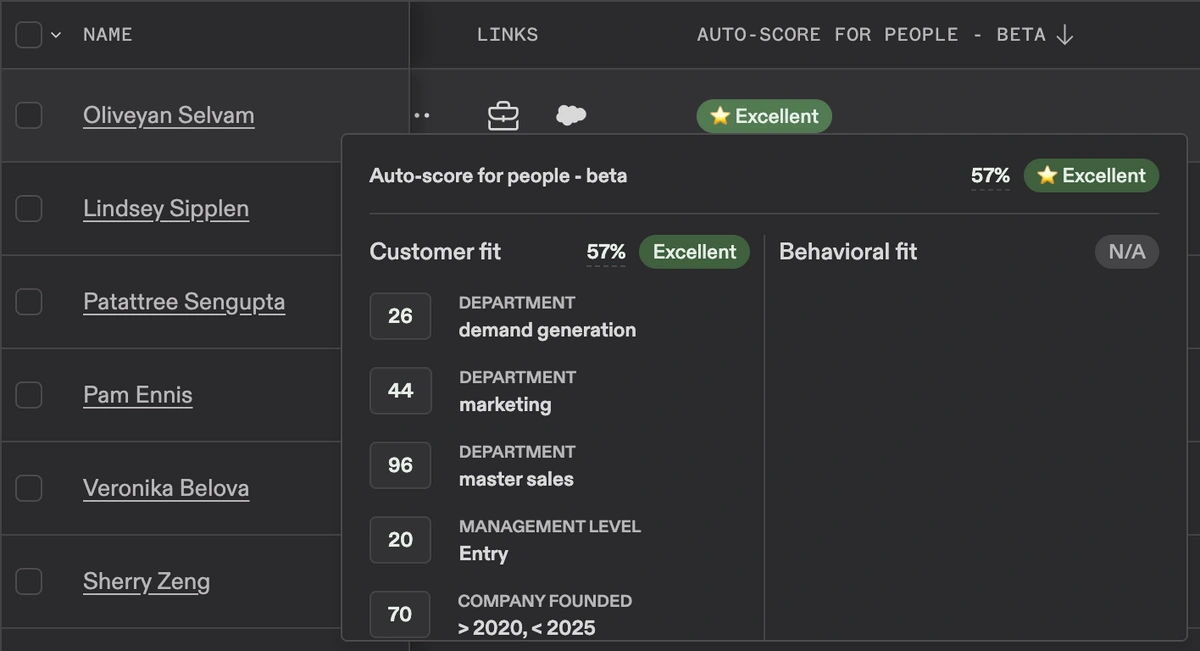
At Apollo, we wanted to scale our scoring mechanism into new use cases and handle the challenges of scale, particularly surfacing the most relevant results with an exponentially large dataset. This is how users today see the results when they prospect (search for contacts) on Apollo. The visual cues, along with a breakdown of scoring, help in targeting the best prospects.
Function score queries in ElasticSearch make this possible by applying a set of custom functions and weights on top of the usual keyword-based matching. For instance, you might:
- Boost documents whose “industry” field matches “Technology.”
- Add points if a lead has opened your marketing emails more than three times in the past month.
- Apply a decay function for time-based factors (e.g., leads get fewer points if they haven’t interacted in the last 30 days).
This flexibility is a powerful tool for building domain-specific relevance. Instead of a one-size-fits-all ranking (like standard TF-IDF or BM25), function score queries let you shape results around business priorities and user behavior. The flip side? More signals and more complex logic often mean more filters—and that can trigger a spike in compute time.
The result? Slow, expensive queries. Some of our worst cases soared to multiple seconds of latency, which is far from ideal when you’re aiming for a snappy user experience. Users who expect real-time search interactions don’t want to wait for a large function score query to compute 30+ weighted filters across potentially millions of documents.
In this post, we’ll detail how we tackled this challenge using ElasticSearch’s Rescore feature in a two-phase approach, and how we validated it with real-world data (including DCG metrics, box plots, and more). We’ll show you how two-phase scoring can preserve the fine-grained ranking benefits of function score queries while taming the dreaded Latency Monster.
Background
At Apollo: Relevance vs. Scoring
In our platform, relevance queries and scoring queries serve different purposes and operate at different levels of complexity:
- Relevance Queries:
- Typically involve basic filters (e.g., location, industry) and a straightforward sort order (such as alphabetical by last name or by a built-in relevancy measure).
- Think of this as “Show me all contacts in California” or “Sort the results by last name”.
- Because these queries don’t have to calculate multiple custom scores, they’re usually faster—our data shows they average around 128 ms in latency.
- Internally, ElasticSearch is mainly using its default ranking (like TF-IDF or a simple filter check) plus a basic sort. It doesn’t have to apply many complex functions or weights.
- Scoring Queries:
- Involve user-defined scoring logic—for example, “Assign +30 points if contact email opens ≥ 3, +20 if the contact has clicked an email, +10 if the contact is in the tech industry, etc.”
- We take these multiple conditions and translate them into a function_score query in ElasticSearch, often with dozens of filters and weights.
- ElasticSearch must then evaluate all these filters on each matching document, calculate the total score, and sort based on this final score.
- As a result, these queries consume more CPU cycles and run slower, averaging ~500ms with a 99th-percentile latency of over ~2.5 seconds.
In short, relevance queries rely on simpler filtering and sorting logic, whereas scoring queries tap into custom, multi-factor scoring that requires more intensive computation for each document in the search results.
Here’s a quick snapshot of how scoring queries compare to relevance-only queries in our environment:
| Query Type | Requests/Day | Avg Latency | TP-99 | % Diff (vs. Relevance) |
|---|---|---|---|---|
| Relevance | 6.1M | 128 ms | 1222 ms | Baseline |
| Scoring | 600K | 546 ms | 2487 ms | ~426% (avg) / ~203% (TP-99) |
Root Cause: Complex function_score Queries
When a scoring query arrives, ElasticSearch must evaluate every scoring filter against every document that meets the broader search criteria. If a user defines 30 filters, each with its own weight—say, “+10 points for having 3+ email opens,” “+20 points for being in a certain industry,” and so on—ElasticSearch applies these 30 checks across potentially hundreds of thousands of matching documents. As a result, the total work explodes:
O(S×D)
(S = number of filters, D = documents)
The more filters (S) we add, or the larger the search result set (D) grows, the heavier the query becomes. It’s like adding more gears to a machine that already runs at full tilt: each new filter adds a bit of friction, and it accumulates fast.
Over time, we noticed that each additional user-defined scoring filter chipped away at our query performance. Where a query once took comfortably under a second, it now risked tipping over 2 seconds in the 99th percentile. That may not sound like a huge delay in absolute terms, but in a real-time application where users expect instantaneous feedback, it feels like a lifetime—and it can take a toll on server resources, too. If we wanted to keep our searches snappy and our clusters healthy, we needed a smarter approach to handle these complex function_score queries.
2-Phase Scoring: Saving the Day
The fundamental idea is elegantly simple: don’t apply all your scoring filters across every single document at once. Instead, break the process into two distinct phases:
- Phase 1 (Initial Pass):
- Use a smaller, simpler set of your highest-impact filters to rank the entire result set.
- For example, if you have 30 filters, pick the top 5–10 that contribute the most weight to your final score.
- This way, you quickly sift through potentially millions of documents, spending fewer CPU cycles per document.
- Phase 2 (Refinement):
- Take only the top N documents from Phase 1 (defined by a
window_sizeparameter) and apply your full, more expensive scoring logic. - Since you’re dealing with a far smaller subset, you can afford to evaluate all the bells and whistles—without bogging down your entire system.
- Take only the top N documents from Phase 1 (defined by a
ElasticSearch has a built-in feature called Rescore that fits this model perfectly:
- Phase 1: ES executes the initial query (the simpler filters) across all shards and returns a ranked list of top documents.
- Phase 2: ES then rescales or refines the scores of those top documents by running the second, more detailed query over only that smaller subset (defined by
window_size).
Why does this matter? Because you only pay the “big” computational bill for documents that actually have a shot at ending up near the top of the search results. By contrast, documents that were never going to rank highly don’t get saddled with expensive scoring calculations.
In practice, this approach drastically cuts the cost of queries that previously needed to run every complex filter on every matching document. Now, you’re effectively offloading heavy computations to a second pass that only looks at the most promising candidates. This means:
- Better performance: Your average query time drops, since the largest share of the work is done on fewer documents.
- Preserved accuracy: You still apply the full scoring logic—just not on the entire corpus—ensuring high-quality results for the user.
It’s a win-win scenario: your customers get the detailed ranking they need, and your servers can take a deep breath because they’re not crunching numbers on every single record.
A Quick Example: Opens & Clicks
Imagine a user who says:
-
Phase 1: “Give me +30 points if the contact has ≥3 email opens.”
-
Phase 2: “Also include +15 points if the contact has ≥2 email clicks.”
-
Our final query might look like this:
{ "sort": [ { "_score": { "order": "desc" } } ], "query": { "function_score": { // PHASE 1 (lighter) "query": { "bool": { "must": [ { "range": { "contact_email_num_opens": { "gte": 3 } } } ] } }, "functions": [ { "filter": { "range": { "contact_email_num_opens": { "gte": 3 } } }, "weight": 30 } ], "score_mode": "sum", "boost_mode": "replace" } }, "rescore": { "window_size": 50000, "query": { "rescore_query": { "function_score": { // PHASE 2 (full) "query": { "bool": { "must": [ { "range": { "contact_email_num_opens": { "gte": 3 } } }, { "range": { "contact_email_num_clicks": { "gte": 2 } } } ] } }, "functions": [ { "filter": { "range": { "contact_email_num_opens": { "gte": 3 } } }, "weight": 30 }, { "filter": { "range": { "contact_email_num_clicks": { "gte": 2 } } }, "weight": 15 } ], "score_mode": "sum", "boost_mode": "replace" } } } } }- Phase 1 is quick because it only checks the “opens” dimension. Then Phase 2 re-scores the top 50k docs using both “opens” and “clicks.”
- Window Size = 50,000. Only those top 50k docs from Phase 1 get the deeper scoring in Phase 2.
- We keep all the core logic but avoid the overhead of applying every single filter to every single doc.
The Elasticsearch Internals (Spilling All the Beans!)
While two-phase scoring feels conceptually straightforward, it’s helpful to look under the hood and see how Elasticsearch actually executes these queries. In a distributed system like Elasticsearch, every operation involves multiple layers—shards, the coordinating node, and finally a global merge. Below is a deeper look into each step of the Rescore process:
1. Query Phase (Shard Level)
- Coordinator Node Sends Query to Shards
- When you issue a search request (with or without rescore) to an Elasticsearch cluster, one node is designated as the coordinating node.
- This node takes your Phase 1 query—usually a simpler
function_scorequery—and sends it out to every shard that holds relevant data. (Indices in Elasticsearch are typically split into multiple shards for scalability.)
- Shard-Level Execution
- Each shard independently executes the Phase 1 query on its subset of documents.
- The shard runs the “simpler” scoring logic (e.g., just a few filters or the default Elasticsearch scoring if you have a
function_scoreblock) against all documents that match your broader filters. - It then ranks those documents locally by their computed score.
- Shard Returns Top N Documents
- Each shard can’t just return a single top document; it needs to send enough documents to the coordinating node so that a global top list can be merged correctly.
- Typically, each shard will return up to
(from + size)documents (plus some buffer, depending on how sorting is done). In a two-phase scenario, you might requestsize = window_sizeor something slightly larger. - For example, if
window_size = 50,000, each shard might return up to 50,000 local top-scoring documents to the coordinating node.
- Local Scoring Only
- Note that at this stage, only the first-phase logic (your simpler function_score or a minimal set of filters) is applied. This keeps CPU usage lower per shard and ensures we’re not doing expensive computations across the entire dataset.
- Distributing the Phase 1 scoring across shards lets Elasticsearch handle large volumes of data in parallel.
- The cost is proportional to the simpler filters you’ve defined for Phase 1—so the fewer they are, the faster this step finishes.
2. Coordinator Node Merge
- Coordinator Collects Shard Responses
- Once each shard finishes its local search, it sends back its top documents (including their partial scores) to the coordinating node.
- The coordinating node now has multiple lists—one from each shard.
- Global Sort
- The coordinating node merges these shard-level lists into a single, globally sorted list.
- This sorting is based on the Phase 1 score. Since each shard has returned its local best documents, the coordinator can pick the top results overall.
- Identify the Top
window_size- Out of the merged list, the coordinating node selects the top documents up to the specified
window_size. - These documents are effectively the “candidates” that will be subjected to the heavier scoring pass (Phase 2).
- Out of the merged list, the coordinating node selects the top documents up to the specified
- Discard the Rest (for Phase 2)
- Documents that didn’t make it into the top
window_sizeare not sent for rescore. - They remain out of scope for Phase 2, which saves a massive amount of compute time—no reason to apply expensive logic to documents unlikely to rank highly.
- Documents that didn’t make it into the top
- The coordinator has effectively pruned the candidate set down to a manageable list.
- Without this pruning step, you’d be applying the heavy scoring pass to every matching document.
- This is how we achieve the main performance gains of two-phase scoring.
3. Rescore (Phase 2 on the Coordinator Node)
Now comes the magic that truly sets two-phase scoring apart:
- Coordinator Prepares the “Rescore Query”
- The original request contained a
rescoreblock specifying a secondfunction_scorequery (or possibly a different set of filters, weights, etc.). - This second query is typically more complex—maybe it has 30 filters with different weights, advanced conditions, or scripts.
- The original request contained a
- Apply Rescore to the Top Documents
- Only the top
window_sizedocuments from the merge step are considered here. - The coordinator effectively re-checks each candidate with the more elaborate scoring logic.
- For each document, it may evaluate multiple scoring conditions—like “+30 points if contact_email_num_opens ≥ 3, +20 if contact_email_num_clicks ≥ 2,” and so on.
- Only the top
- Recalculate Final Scores
- The scores from Phase 1 are overwritten or combined (depending on
boost_modeandscore_mode) with the newly computed Phase 2 scores. - For instance, you might specify
"boost_mode": "replace", which means the Phase 2 score replaces the Phase 1 score entirely. Or"boost_mode": "multiply", which multiplies the two scores.
- The scores from Phase 1 are overwritten or combined (depending on
- Re-Sort the Subset
- Once the coordinator has the recalculated scores for these top documents, it re-sorts them by the new, refined scores.
- This sorting is now highly accurate because it used all the user-defined scoring logic.
- Combine Back Into the Overall Result
- The coordinator merges these newly sorted top documents back into the final result list.
- Effectively, the coordinator replaces the Phase 1 scores for these top documents with the newly computed Phase 2 scores, ensuring the final top results reflect the full complexity of your scoring.
- By focusing the heavy-lifting on a smaller subset of documents, we keep overall CPU usage in check.
- We still maintain ranking accuracy for the top results, because the Phase 2 query sees all the complex filters.
- Documents that don’t make this cut remain sorted by the simpler Phase 1 score, which is usually acceptable because they weren’t likely to rank highly anyway.
4.Final Results
- No Extra Fetch
- Unless you request more fields or
_sourcefor those top documents, the coordinator already has enough metadata to finalize the ranking. - There’s no need to re-fetch data from the shards for the Phase 2 step; the coordinator just updates scores.
- Unless you request more fields or
- Final Sorted List
- The user (or calling service) receives the final sorted list of documents.
- If your
sizeparameter is smaller thanwindow_size, you get exactly the top results after the refined Phase 2 scoring. - If your
sizeis equal towindow_size, you get the entire re-scored subset.
- Unscored Documents
- Anything beyond the top
window_sizenever sees the second pass. That’s the critical performance optimization. - If you set a very large
window_size(say 100k or more), you’ll still be running the heavy logic on a lot of documents. Conversely, ifwindow_sizeis too small, you might worry about missing documents that could leap into the top if they got a big boost from a certain filter. Balancing this is key to two-phase scoring.
- Anything beyond the top
- This step shows the beauty of the Rescore approach: only the most relevant documents are subject to the overhead of complex scoring.
- The entire pipeline—shard-level local ranking, global merge, rescore on the top subset—happens within the standard Elasticsearch search flow.
Putting It All Together
- Phase 1 quickly identifies a broad set of high-scoring documents using simpler rules.
- The coordinating node globally merges those results and selects the top
window_size. - Phase 2 (Rescore) applies the full, heavy scoring formula to just that smaller set, updating their scores.
- Elasticsearch returns a final sorted list, reflecting your most detailed scoring—but only where it truly matters.
By dividing the workload into two passes, we effectively dodge the explosive O(S × D) cost for the entire dataset. Instead, we only pay for the complex logic on a subset that’s likely to contain the top results. The end result? Faster queries, less CPU overhead, and still top-notch ranking accuracy. That’s the magic of Rescore under the hood—and the reason two-phase scoring is a go-to solution for taming complex queries.
Our Grand Experiments
We didn’t just guess this would work; we rigorously tested it in production. We:
- Captured 1% of all scoring queries.
- For each captured query, we generated multiple variations of a two-phase approach:
- Varying the number of Phase 1 filters (e.g., 5, 10, 15).
- Varying the window_size (e.g., 5k, 20k, 50k, 100k).
- For each variation, we measured:
- Latency: End-to-end query time.
- DCG (Discounted Cumulative Gain): A standard measure of ranking quality.
To reduce noise, we ran each experiment query five times and discarded outlier runs.
- Latency_Drop: The percentage drop in latency when comparing two-phase scoring to the original single-phase approach. (Closer to 100% is better, i.e., bigger reduction in time.)
- DCG_DROP: How much the DCG dropped under two-phase scoring vs. single-phase. (Closer to 0% is better.)
1. Latency Impact
We’ll start with the high-level results:
- Median latency dropped by ~50% when using 5–10 filters in Phase 1.
- Varying window_size up to 50k didn’t drastically affect latency, but going to 100k started increasing cost more significantly.
Below is a conceptual box-and-whisker plot illustrating Latency Drop vs. Number of Phase 1 filters:

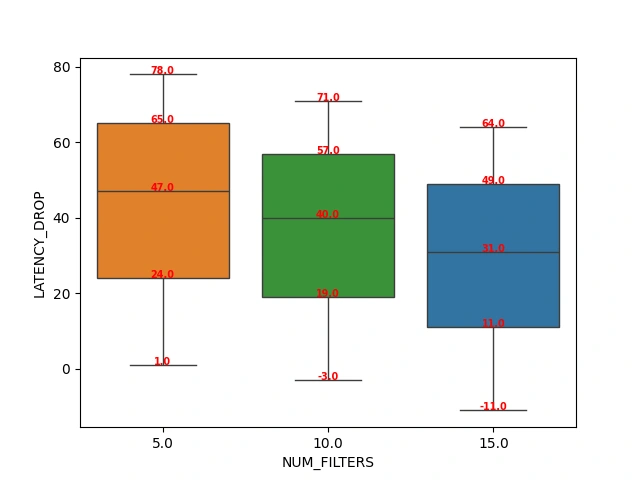
(Illustrative example—imagine a box plot where the median is around 47% improvement with 5 filters.)
- X-axis: Number of filters in Phase 1.
- Y-axis: Latency improvement (in %).
Key Observation: With fewer Phase 1 filters, we get the biggest latency improvements. Once you exceed about 10 filters in Phase 1, the advantage starts diminishing.
2. DCG Impact
Anytime we cut corners on scoring, we risk hurting the final ranking. We used DCG to measure how much the two-phase approach deviates from the single-phase baseline. We checked DCG at various cutoffs:
- k = 10k (top 10k documents)
- k = 250 (top 250 documents)
Finding: The DCG drop was effectively 0% for most queries, only becoming noticeable for a tiny fraction of edge cases (beyond the 99th percentile of queries).
Here’s a sample chart showing DCG Drop vs. Number of Phase 1 filters:

- X-axis: Number of filters in Phase 1.
- Y-axis: DCG_DROP (Lower is better).
As you can see, almost all data points hug the 0% line, indicating no real drop in ranking quality. At the 99th percentile, we see a slight increase, but it’s still minimal.
3. Window Size Sensitivity
We also tested different window sizes (5k, 20k, 50k, 100k) to see how that impacted both latency and DCG. Two key insights:
- Latency:
- Going from 5k to 50k didn’t drastically raise the median latency.
- Jumping to 100k introduced a nonlinear latency jump (due to re-scoring many more documents).
- Going from 5k to 50k didn’t drastically raise the median latency.
- Jumping to 100k introduced a nonlinear latency jump (due to re-scoring many more documents).
- DCG:
- Even with a window size of just 5k, we observed no significant drop in DCG for most queries. We only saw any measurable drop below 500 documents.
- Even with a window size of just 5k, we observed no significant drop in DCG for most queries. We only saw any measurable drop below 500 documents.
Here’s an example plot of DCG Drop vs. Window Size:
Most points remain around 0% drop until we get to very small window sizes (under 500). That’s when we start seeing a real hit to ranking quality.
Putting 2-Phase Scoring into Action
Choosing Phase 1 Filters
One of the critical steps in our two-phase approach is selecting which filters (or signals) go into Phase 1. We’ve found that sorting them by their weight—i.e., how many points they add to a document’s score—is a strong initial heuristic. The logic is:
- High-Impact Filters First: Heavier-weight filters typically make a bigger difference in a document’s final score, so putting them in Phase 1 ensures the ranking from the first pass is already quite accurate.
- Fewer Is Faster: Limiting Phase 1 to a handful of core filters (e.g., 5–10) prevents needless overhead. Adding too many filters to Phase 1 brings you back toward the original “everything in one pass” problem.
In the future, we might refine this selection further—perhaps by analyzing how frequently a filter actually discriminates between high- and low-quality documents, or by applying machine learning to dynamically pick filters that best predict user engagement.
Split Queries
Previously, our code generated a single function_score query jam-packed with all user-defined filters. Now, it produces:
- Phase 1: A streamlined
function_score(or whatever minimal logic is needed for the first pass). - Phase 2 (Inside
rescore): The full, detailed scoring logic.
Both pieces end up in one Elasticsearch request, with the second only executing on the top window_size results from Phase 1. This required a careful refactor to ensure we correctly build two separate segments of JSON—but it means we don’t have to maintain two entirely separate query flows in the application code.
Feature Flags & Monitoring
Rolling out two-phase scoring was a high-stakes change: if something went wrong, we could degrade search relevance or introduce subtle ranking bugs. To mitigate risks:
- We gated the new logic behind a feature flag, letting us slowly ramp it up for a subset of users.
- We logged every query’s Discounted Cumulative Gain (DCG) in real time, comparing the two-phase approach to the old single-phase. If we detect a spike in DCG loss, we could revert quickly.
- We also watch latency and infrastructure metrics—CPU usage, memory, and request throughput—to confirm we’re achieving the expected performance gains without negative side effects.
Edge Cases
- Federated Search (Siren)
- Since our Federated Join layer (Siren) doesn’t yet support rescore, we skip two-phase scoring for these queries. That’s about 2.6% of total scoring searches—small enough not to derail the broader rollout.
- In the long term, we’d love to see rescore support added to Siren so no query is left behind.
- Tiny Result Sets
- If the entire search matches fewer than 1k documents, the overhead of making two passes may not yield real benefits. In fact, it can add extra steps for minimal gain.
- We may optimize by detecting such scenarios (via a preflight count) and skipping the second phase for trivially small result sets.
Observations & Lessons Learnt
window_size- Setting
window_sizetoo small (< 500 or 1k) may cause good documents to be overlooked in Phase 2, hurting DCG. - Setting it too large (e.g., 100k+) dilutes your performance gains and can still be quite heavy if each shard returns tens of thousands of documents.
- We consistently see a sweet spot around 5k–50k for most of our queries. It balances performance gains with accurate scoring.
- Setting
score_mode&boost_mode- With
"score_mode": "sum"and"boost_mode": "replace", the second-phase score overrides the first-phase_score, summing only the filters from the second pass. - If your scoring approach needs to blend Lucene’s default
_scorewith custom logic, you might choose"score_mode": "multiply"or"boost_mode": "multiply". But that can complicate interpretability.
- With
- Filter Selection
- Concentrating on a few high-impact filters in Phase 1 gives the largest latency improvements.
- In the rare query where all filters have the same weight or importance, Phase 1 might choose them all, but that reverts to something close to single-phase—so we aim to avoid that scenario.
- Shard-Level Behavior
- Each shard independently applies Phase 1, returning its top docs. The coordinator merges them into a global list and applies rescore only to the top subset.
- This distributed approach helps scale large indexes, but it also means you must ensure each shard returns enough docs for global sorting.
- Big Gains, Minimal Downsides
- Our data consistently shows query times can be cut by ~50% without harming DCG.
- Users barely notice any difference in result quality, but they definitely notice faster response times—leading to higher satisfaction.
- Elastic Upgrades & ES Version
- Rescore has improved across Elasticsearch versions. Make sure you’re on a release that supports the type of queries you need. Some older versions had known quirks or less efficient ways of merging shard results.
- Watch Memory & CPU
- Rescoring 50k documents is still a non-trivial operation—especially if each filter includes a script or an expensive check.
- However, it’s far better than applying those filters to every matching document across all shards. Monitoring resource usage is key to finding an optimal
window_size.
Final Results
- Latency:
- We observed a ~50% median reduction in scoring query times, dropping from ~546 ms to ~273 ms under load testing conditions.
- In certain complex queries—like those with 30+ filters over millions of documents—the improvement was even more pronounced.
- This freed up cluster resources, reducing overall CPU usage and letting us handle more queries simultaneously.
- Quality:
- Our DCG measurements showed negligible differences between single-phase and two-phase results for 99% of queries.
- For the tiny fraction of edge cases (at the 99th percentile), we saw a small DCG dip—but still within acceptable bounds for ranking. In those cases, we can tweak
window_sizeor Phase 1 filter selection if needed.
Overall, the approach let us maintain high-quality, customer-defined scoring while avoiding the Latency Monster that once threatened to slow everything down.
Where We’re Headed Next
- Adaptive Phase 1 Filters
- We currently rely on “top by weight” to pick filters for Phase 1, but we’d like to incorporate usage data or machine learning to identify which filters truly separate “good” vs. “bad” leads in real user sessions.
- For instance, if a certain filter rarely changes a document’s final rank, why include it in Phase 1?
- Adaptive Window Size
- Right now, we fix
window_sizefor broad classes of queries. In the future, we might run a quick (cheap) count or heuristic to guess how big the result set might be and dynamically setwindow_size. - For small result sets (< 1k docs), we might skip two-phase altogether. For enormous result sets, we might push
window_sizehigher to ensure we don’t lose important docs in Phase 2.
- Right now, we fix
- Federated Search Support
- We’d love to see rescore fully supported in Siren Federate. This would enable two-phase scoring for every single search—no exceptions. We’re collaborating with them to explore feasibility.
Conclusion: The Latency Monster Bowed to Rescore
By breaking our scoring logic into two phases and letting Elasticsearch handle a second, refined scoring pass only on the most promising documents, we:
- Cut latency by ~50% on average for scoring queries, sometimes even more for complex scenarios.
- Maintained virtually the same ranking quality, as proven by our negligible DCG drop in 99% of cases.
- Gained confidence to scale up user-defined scoring further, without worrying we’ll tip over into multi-second response times.
If your own search engine is buckling under the weight of function_score queries, two-phase scoring is a powerful way to keep your performance high and your users happy. Just configure rescore carefully, choose your Phase 1 filters wisely, and monitor your relevance metrics (like DCG). It might just be the best of both worlds: blazing-fast queries and spot-on results.
Want to Connect? We are hiring!
Explore Apollo.io to see how we help teams find and engage the best leads—now faster than ever, thanks to two-phase scoring. Apollo solves numerous problem statements like these, and we are heavily investing in AI to develop products for our customers. We would love for smart engineers like you to join our "fully remote, globally distributed" team. Click here to apply now!
Until next time, may your searches be swift, your CPU usage calm, and your users thrilled with the results!